 受託開発・お問い合わせ
受託開発・お問い合わせ
RAGの構成を図解|非エンジニア向けに仕組みから活用例まで解説
2022年末頃にChatGPTが台頭してから、大規模言語モデル(LLM: Large Language Model)の活用があらゆる分野で広がっています。日常生活でのふとしたアイデア出しやメール・企画書の作成など、今では欠かせないパートナーとなっている方もたくさんいることでしょう。
しかし、そんなLLMにも限界はあります。それは、社内文書や設計図面など秘匿的な情報に対する質問への回答が困難だということです。LLMは一般公開された情報から学習させるため、このようなプライベートであり、非公開・社内固有などの情報は持っていません。対策を講じずLLMに回答を促すと、「分からない」と返答するならまだしも、虚偽の文章を生成するハルシネーション(幻覚)という現象が生じる可能性があります。
こうしたLLMが知らない情報に対しても、外部から新たに情報を加えて正確な回答を促す仕組みとして「RAG(ラグ)」が提案されています。このRAGの仕組みを図解し、わかりやすく説明していきます。

RAGを利用しない場合(左)と利用した場合(右)の比較

RAGとは?何ができるのか?
RAGはRetrieval-Augmented Generationの略で日本語では検索拡張生成と訳されます。プロンプトと呼ばれる質問をLLMに問いかけて回答を生成してもらうプロセスに「検索」の機能とプロンプトを「拡張」する機能が付与されたものがRAGです。
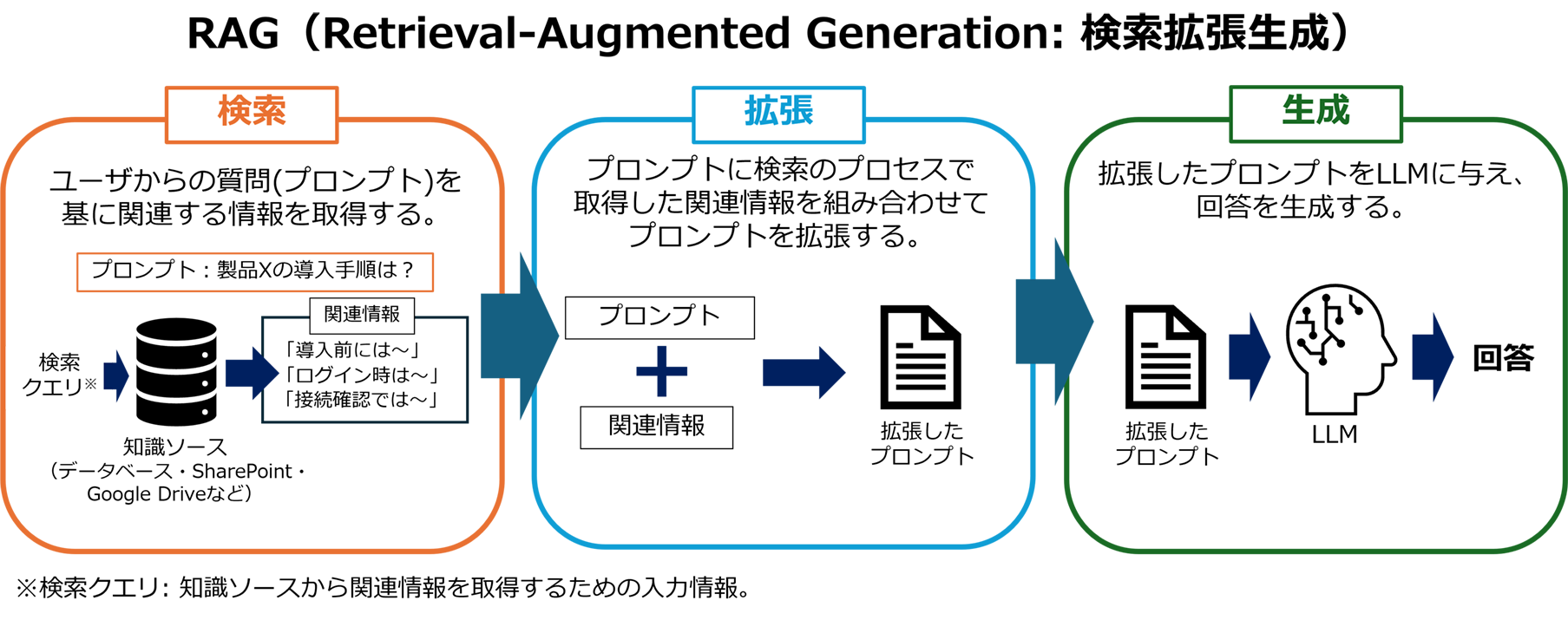
RAGの概要図。大きく「検索」と「拡張」と「生成」のプロセスに分けられる。
RAGはLLMに直接ユーザからの質問を入力するのではなく、ユーザの質問に基づいた関連のある情報を取得するために、質問に基づいた専用の検索クエリをデータベースのような外部の知識ソースに送信して検索、この検索結果と質問を組み合わせてプロンプトを拡張することで正確な回答を促すわけです。
試しにRAGを用いてLLMに外部情報を提供した場合と、外部情報なしでLLMにそのまま質問した場合で、どのように回答が変わるかを比較してみます。例として「風ヶ原市」という架空の市のデータを、外部情報としてRAGの知識ソースに格納します。風ヶ原市とは次のようなステータスを持つ市です。

風ヶ原市のステータス
(左が市のステータスが記述された生データ、右が生データのプレビュー画像)
RAGによってLLMにこの市の外部情報が提供される場合と、外部情報なしでLLMにそのまま質問した場合について、風ヶ原市のキャッチコピーを聞いた時の回答を比較します。まずは外部情報なしでLLMに質問した場合の結果を見てみます。
外部情報なしでLLMにそのまま質問した場合
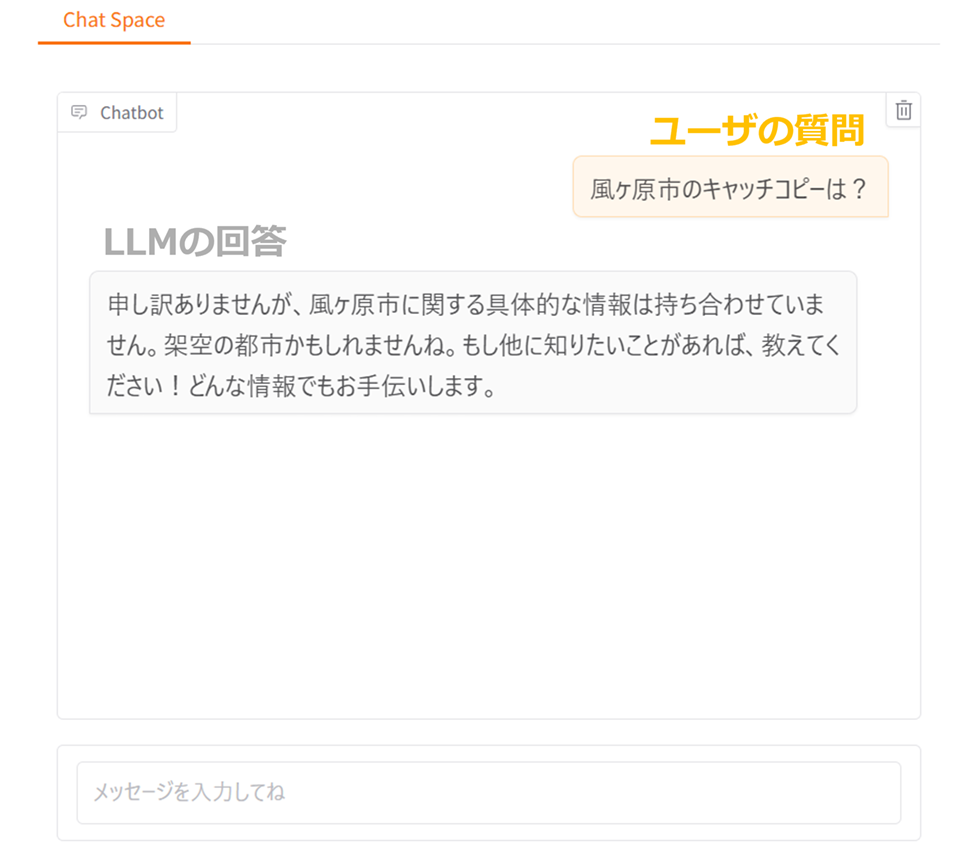
外部情報として風ヶ原市のステータスがLLMに提供されない場合の結果
こちらの図より、明確にキャッチコピーについては分からないという回答が返ってきました。やはり知識がないと求める情報が得られないことが確認できました。
次にRAGによってLLMに外部情報が提供される場合の結果を見てみます。
RAGによってLLMに外部情報が提供される場合
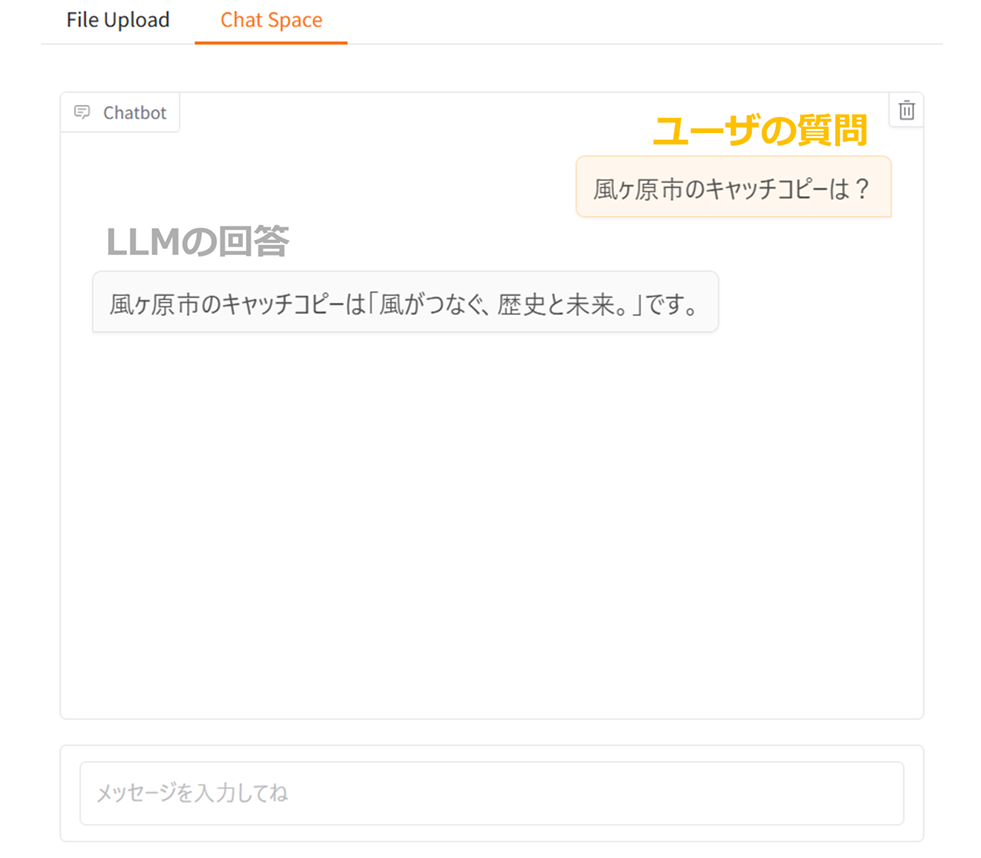
RAGにより外部情報として、風ヶ原市のステータスがLLMに提供された場合の結果
市のキャッチコピーが「風がつなぐ、歴史と未来。」であることを踏まえると、外部情報が提供されない場合と比較して、正しくキャッチコピーを返答したことが見て取れます。このように、外部情報を加えることでLLMが知識ソースに基づいた正確な回答を生成できることが確認できました。LLMが優れた文章理解力を持つからこそ、外部情報と質問をそれぞれ解釈し適切な回答が得られるのです。
RAGの仕組みと構成
RAGにおいて肝心な「外部情報を取得する」ことと「取得した情報を基にユーザの質問への回答を生成する」ことは、どのようにして実現されるのでしょうか?それぞれを実現するために一般的に用いられているRetriever(検索器)とGenerator(生成器)という二つのコンポーネントについて解説します。
Retriever
外部情報である知識ソースからユーザの質問に関連する情報を複数検索するコンポーネント。
Generator
検索された情報(Retrieverが取得した情報)とユーザの質問の内容を踏まえて回答を生成するコンポーネント。LLMそのものを指すことが多い。
これらの構成要素とRAGのフローは次の通りです。
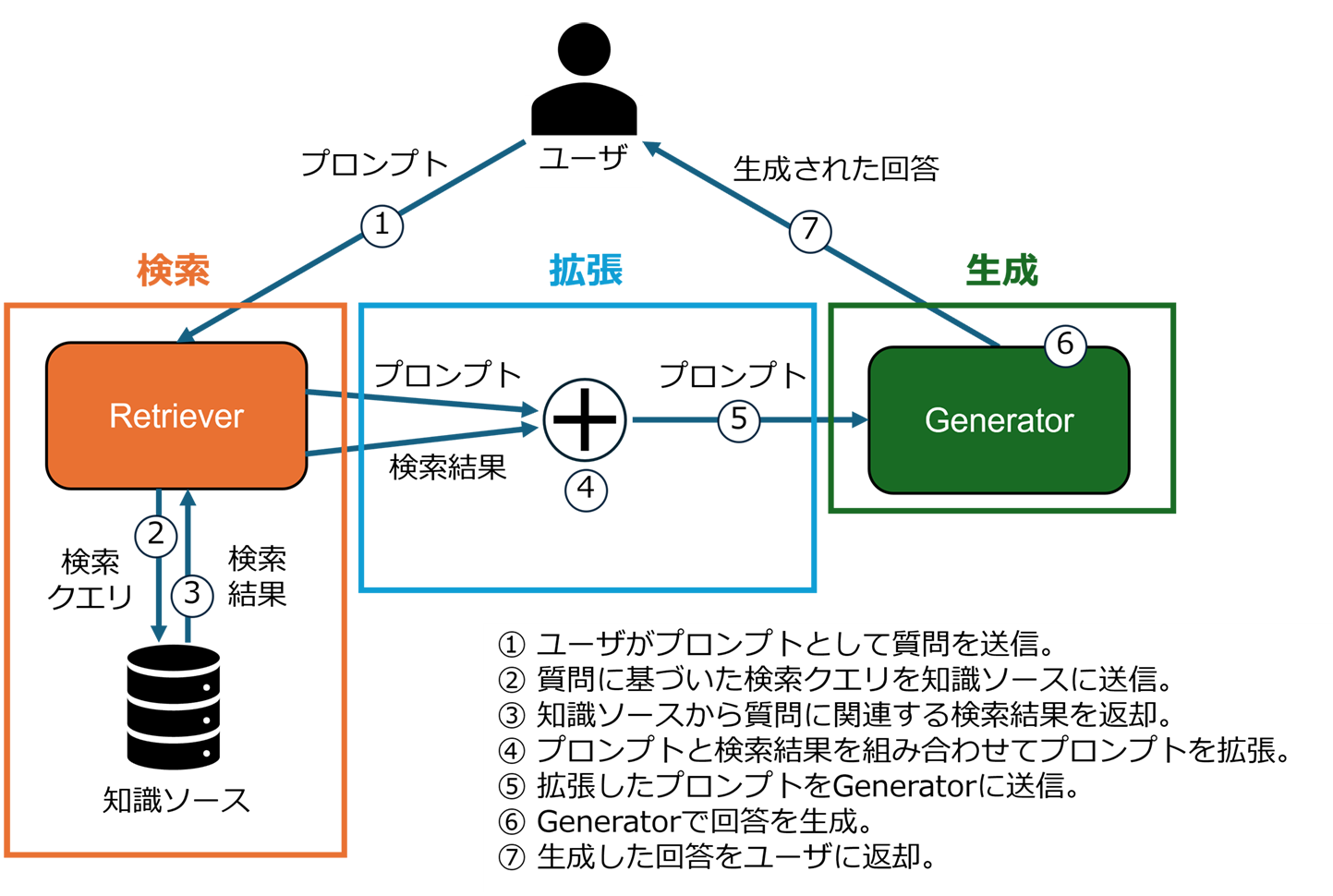
RAGの各構成要素とそのフロー
こちらの図からわかる通り、ユーザからの質問は真っ先にRetrieverに渡され、知識ソースからの検索が実行されます。検索により得られた情報は、ユーザの質問と共にGeneratorへ入力されます。Generatorは与えられた質問と検索された情報を基に回答を生成します。
RAGの性能を支えるコンポーネントの重要性
先ほど紹介したGeneratorは、ある程度検索された情報の真偽を判断することは可能です。しかし不適切あるいは関係がない情報がGeneratorへ入力されると、どのような影響が生じるでしょうか?この場合Generatorはかえって混乱し間違った回答が出力されることになります。知識ソースに格納する情報の正確性や情報の格納方法、Retrieverそのものの検索能力というのはRAGにおいて大変重要です。
またRetrieverにて適切な情報が検索されたとして、Generatorの文章理解力や生成力が乏しかったらどのような回答が得られるでしょうか?おそらく的外れな回答で使い物にならないことでしょう。
GeneratorとしてのLLMの性能は、Retriever同様にRAGの性能を大きく左右するため、採用するLLMもしっかりと吟味する必要があります。
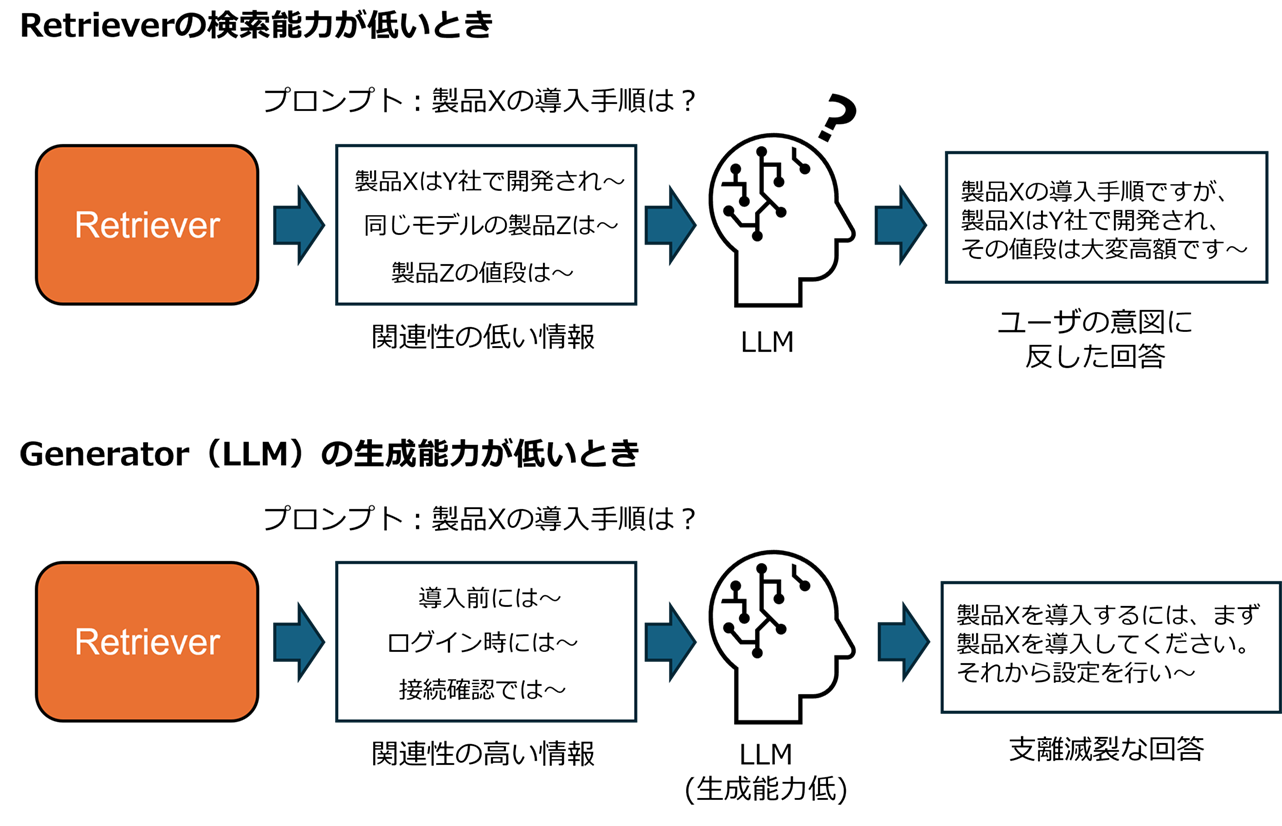
RetrieverおよびGeneratorの性能不足による回答生成への影響イメージ
そのほかにも、プロンプトはむやみに拡張するのではなく、LLMが正しく解釈できるよう整理された状態で拡張する必要があるなど、RAGの性能を決める要素は各コンポーネントやプロセスにおいて複数存在し、要件や性能を満たすように、設計・開発する必要があるのです。
RAGのその未来:AIエージェントとの融合
これまで紹介した、「検索」→「拡張」→「生成」のプロセスはRAGの基本形です。しかしこうした固定の手続きであると、横断的な情報の検索ができない、高度な推論を要する質問への回答が難しいといった問題を含んでいます。
このような課題の克服のため、近年AIエージェントを融合させたRAGの活用が検討されています。AIエージェントとは、タスクを達成するために自律的に考え行動するシステムです。現在はLLMを頭脳として用いたものが主流で、自ら思考し、行動し、反省し、再度行動する動的なプロセスでタスクを達成します。
AIエージェントをRAGに組み込むことによって、1つの知識ソースに固執することなく複数の情報源にアクセスして多様な情報を獲得することができます。またツールとしてインターネット検索、WebAPIの呼び出し、計算機などを設置すれば、AIエージェントはこれらを呼び出すことができ、より高度な情報処理や質の高い回答の生成が期待できます。
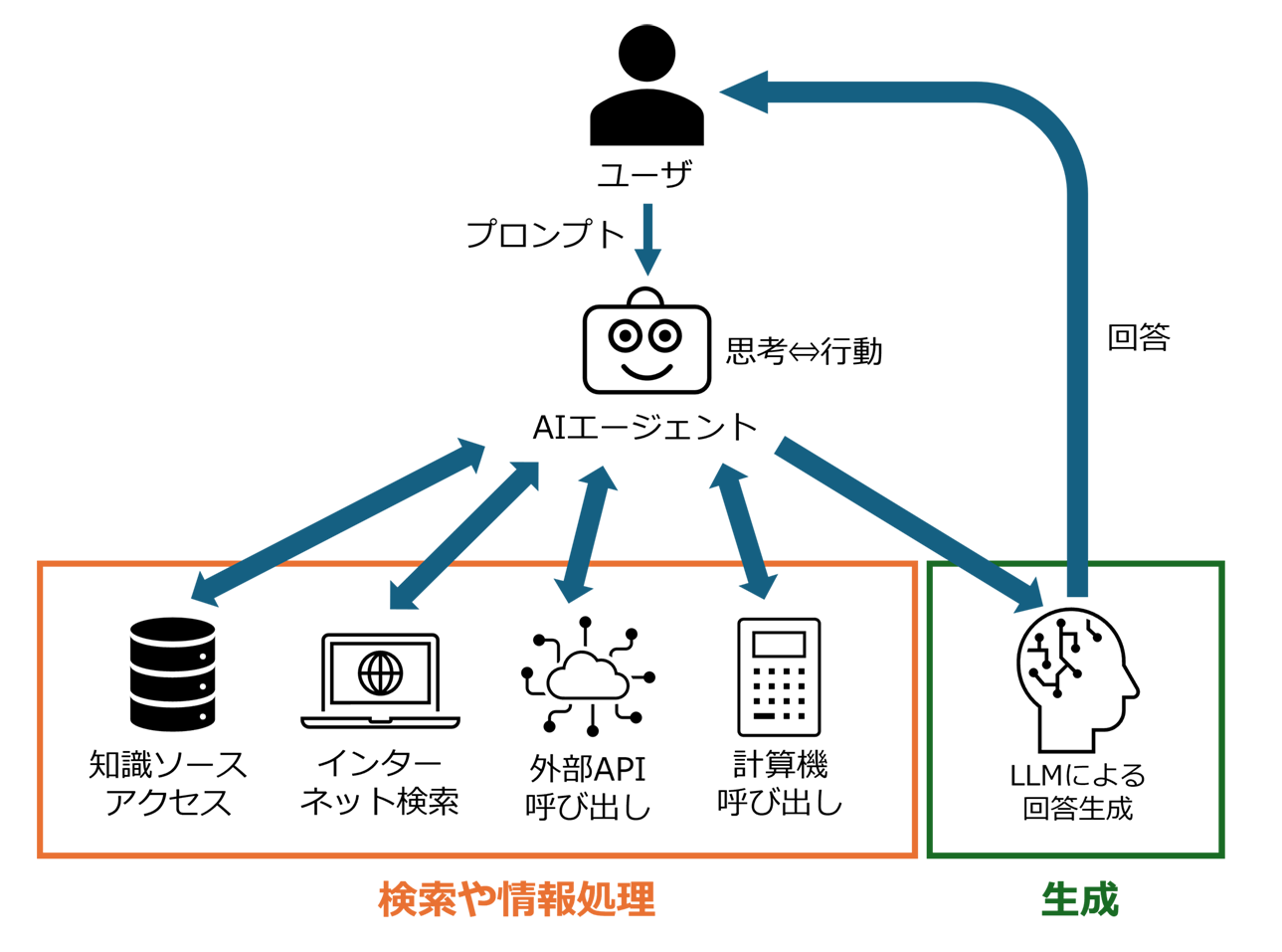
AIエージェントによるRAGの構成のイメージ
RAGそのものに知能を加えることで、よりユーザに寄り添った回答を促すのがAIエージェントです。
RAGの活用例
知識ベースから取得した情報をもとにLLMに回答を生成してもらうRAGという技術は情報活用のツールとして新しい牽引役となるでしょう。そのようなRAGの代表的な活用例は以下の通りです。
活用例1:社内規約の検索とその要約
社内規約やルールが記載された文書を知識ソースとして与えます。RAGを通じて検索をかけることで、これまで要していた情報収集の時間短縮や、問い合わせを受けていた担当者の工数削減が期待できます。LLMによって要約された回答が返却されるため、ユーザは明瞭な情報を得られるでしょう。
活用例2:カスタマーサポート支援
顧客から問い合わせがあった質問や苦情内容について、ホームページ上に専用のチャットボットを設置することで、24時間365日迅速な回答が可能です。チャットボットではなく直接問い合わせがあった場合でも、RAGを通じて検索し、顧客返信の文面も同時に生成してもらうことで回答作成の工数を削減します。
活用例3:製造・建設業における業務プロセスの円滑化
設計書、仕様書、見積書、報告書などを知識ソースに与えることで、過去事例から類似事例を見つけやすくなり、製造や施工に係る見積もりや設計の効率化が期待できます。また蓄積したナレッジも知識ソースに追加すれば、トラブル対応の迅速化や次世代への技術継承も期待できます。ただしナレッジ追加の際は熟練した技術者や職人の暗黙知の可視化が重要です。
まとめ
本記事ではRAGの基本を図解で説明するとともに、AIエージェントによるRAGの将来まで紹介しました。RAGはまさしくこの大規模言語モデルの時代に、手軽かつ信頼性の高い情報活用を促す技術であり、今後とも更なる活躍が見込まれます。
アラヤではRAGに関するご相談・開発・導入支援・運用サポートまで、一貫して承っております。丁寧かつ誠実に対応いたしますので、まずはお気軽にご連絡ください。


