 受託開発・お問い合わせ
受託開発・お問い合わせ

エッジAI導入のリアル事例と活用シーン|無料相談で御社の可能性を診断



活用事例2:蒸留技術で異常検知モデルを小型化・高精度化
エッジAIを使って製品の外観検査(異常検知)を行うシステムに対し、「蒸留」という技術を用いて軽量化と精度向上を同時に実現しました。
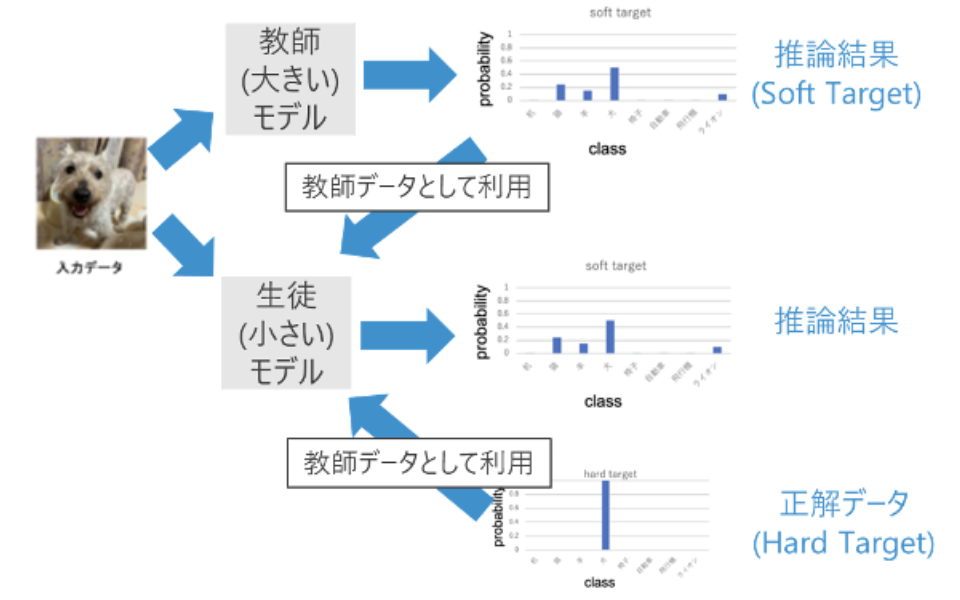
今回は、画像から正常・異常を分類するモデルに蒸留を適用し、誤検出率を約40%低減することが可能になりました。
これにより、限られた端末数でも多くのモデルを動かせるようになり、現場の処理速度向上とコスト削減を同時に達成した成功事例です。
今後のエッジAI普及に向け、軽量モデルの需要はさらに高まっており、蒸留は有効なアプローチといえます。
活用事例3:量子化+TensorRTで商品検出AIを2倍高速化
小売業向けアプリで商品を画像から検出するAIにおいて、処理速度の課題を解決するため、モデルを「量子化(Int8/FP16)」し、さらにNVIDIAのTensorRTライブラリを使って最適化を実施。

これにより、モデルの精度を保ったまま、推論スピードが最大約2倍に向上しました。
この取り組みは、店舗でのリアルタイム商品棚監視や在庫チェックなど、即応性が必要なエッジAI事例として非常に有効です。
※量子化:AI内部の計算を軽くする技術で、処理時間を短縮しつつエッジ端末での動作を可能にします。
※TensorRT:ネットワークを高速化する仕組みで、精度はそのまま、レイテンシーを大きく削減できるのが特長です。
製造業:不良品検出と自動化ラインの最適化
①画像認識による外観検査

自動化ラインの最適化
製造ラインにカメラとエッジAIを組み込み、製品の外観を自動で検査するシステムが活用されています。
これまで人が目で確認していた作業をAIがリアルタイムで不良品を判定することで、検査のスピードと精度が向上します。
生産性が40%アップした実績もあります。
②異常振動のリアルタイム検知
機械に取り付けたセンサーで振動のパターンをエッジAIが常に分析し、異常を感じ取ると即時にアラートやライン停止を行う仕組みが使われています。
これにより、大きな故障や長時間の停止を未然に防ぎ、保守コストを削減。
製造現場での安全性・安定稼働を支える代表的なエッジAI事例です。
小売業:在庫管理・客動線解析の効率化

冷蔵庫内センサーでの在庫管理
①店舗内AIカメラでの購買行動分析
店内に設置したAIカメラでお客様の行動をリアルタイムに解析し、人気商品の配置や導線を改善した事例です。
来店客がどこに立ち止まり、何を手に取るかを可視化でき、プロモーション施策の精度も向上。
結果、売上アップにつながった店舗もある注目のエッジAI事例です。
②冷蔵庫内センサーでの在庫管理
冷蔵庫にエッジAIを搭載したセンサーを設置し、商品の在庫状況を常時モニタリング。
在庫が減ったタイミングを自動で検知し、必要な商品だけをリアルタイムで補充できます。
その結果、欠品ゼロの店舗運営が可能となり、販売ロスや手作業による確認の手間も大幅削減可能になります。
農業:スマート農業での環境最適化

安心・安全な農業の実現
①農地センサーとAI連携での潅水制御
畑に設置した土壌センサーが水分量を測定し、エッジAIが天気予報と連携して最適な水やりのタイミングを判断します。
この仕組みにより、ムダな潅水を減らし水の使用量を大幅にカットできるようになります。
省エネ・省人化に役立つ、農業分野で注目を集めるエッジAI事例です。
②病害虫の画像認識による早期発見
ドローンやカメラで葉の様子を常時撮影し、AIが病気や虫の兆候を画像から見つけ出すエッジAIシステムが活用されています。
早期発見により、農薬を最小限に抑えて作物を守る取り組みが進んでおり、安心・安全な農業の実現にも貢献する事例です。
インフラ:老朽設備の監視と保守

インフラの監視と保守
①ブリッジインスペクションAI
橋梁の点検において、ドローンで撮影した画像をその場でエッジAIが解析し、ひび割れなどの異常を検出するシステムが活用されています。
これにより、高所作業の省人化と作業員の安全確保が両立できる事例として、インフラ点検の効率化に大きく貢献しています。
②電柱・トンネルの劣化監視
電柱やトンネルに取り付けたセンサーが、振動や傾きの変化をリアルタイムで検出し、エッジAIが異常を即座に分析する監視システムです。
この仕組みにより、設備の劣化や構造不良を早期に把握でき、重大事故の予防や点検業務の負担軽減にもつながる注目のエッジAI事例です。

株式会社アラヤ
先端AIとニューロテックを基盤とするディープテックベンチャーです。ムーンショット型研究開発への参画をはじめ、企業・大学との共同研究実績を多数有し、現役研究者とエンジニアが一体となった研究支援を提供しています。大学・研究機関における持続可能な研究体制の構築と研究力強化に貢献してまいります。
主な事業概要
AIアルゴリズム開発(ディープラーニング・エッジAI・自律AI)、建設DXソリューション、研究現場の業務効率化支援(Research DX)など、基礎研究から社会実装まで一貫して手がけています。

