 受託開発・お問い合わせ
受託開発・お問い合わせ

VLMとは?初心者でもわかる視覚言語モデルの仕組みと活用例
VLMとは?導入現場に役立つ基本知識

Vision Language Model
VLM(Vision Language Model)は、画像や動画などの視覚情報と、テキストで書かれた言語情報をつなぐAI技術のことです。
これまでの画像認識技術(たとえばCNNなど)では、画像の中に「何があるのか」はわかっても、その背景や関係まで理解するのは難しいものでした。
一方、VLMは視覚と言語を一緒に理解することで、より深い意味や文脈までとらえられます。
VLMとLLMの違い|導入時の選択ポイント

VLMとLLMの違い
VLMと似たような性質を持つ技術に、LLM(大規模言語モデル)というものがあります。
ここでは、VLMとLLMの違いについてご紹介します。
LLM(大規模言語モデル)
LLM(大規模言語モデル)は、多くの文章を学ぶことで、言葉の意味や使い方を理解できるAI技術です。
たとえば、文章を作ったり、質問に答えたり、文章の内容をまとめたりするときに使用されます。
よくニュースなど広い意味で「AI」と呼ばれているのは、このLLMのことが多いです。
VLM(視覚言語モデル)
VLM(視覚言語モデル)は、画像や動画といった視覚情報を、言葉の情報と一緒に理解できるAI技術です。
たとえば、画像を見ながら説明をまとめたり、画像とテキストの情報を組み合わせて問題を解決することができます。
このように、VLMは画像と言語を結びつけることで、LLMよりも幅広いタスクに対応できるのが特徴です。
VLMを導入するメリット・デメリット

VLMを導入するメリット
現場で活用することで業務の効率化や新しい価値を生み出せる一方で、いくつか注意すべきデメリットもあります。
ここでは、VLMを導入する際に知っておきたいメリットとデメリットをまとめてご紹介します。
メリット
VLMを導入すると、業務に役立つさまざまなメリットがあります。
具体的には以下のような点が挙げられます。
● 画像とテキストの情報を同時に活用できるので、現場での柔軟な対応が可能
● 新しい単語やクラスが出てきても、再学習なしで対応できる(ゼロショット学習)
● 画像と言葉を組み合わせた説明や質問応答ができ、作業の精度やスピードが向上
● AI導入後も、さまざまな業界や業務に応用が広がる可能性がある
これらのメリットを活かすことで、VLMは現場の業務改善に役立つ技術として期待されています。
デメリット
一方で、VLMを導入する際には注意が必要なデメリットもあります。
具体的には以下のような点が考えられます。
● AIモデルの特性や仕組みを正しく理解しないと、使いこなすのが難しい
● 高性能なモデルは計算コストやシステム整備が必要になる場合がある
● 導入前に、データの整備や業務に合わせたカスタマイズが必要
● まだ新しい技術のため、運用面やデータ保護への配慮が求められる
これらの点に注意しながら、VLMを業務に活かしていくことが大切です。
VLMを導入する際の注意点

VLMの導入注意点
VLM(視覚言語モデル)を導入する際には、いくつかのポイントに気をつける必要があります。
ここでは、データ面・技術面・運用面など、それぞれの視点での注意点をご紹介します。
データの品質と準備
VLMの出力は、入力する画像やテキストの質により大きく変化します。
データに偏りがあると、出力結果も偏ってしまうリスクがあります。
そのため、正確で質の高いデータを準備することが重要です。
技術面での理解と体制
VLMは高度な仕組みを持つため、正しく理解し、業務に合わせて調整できる知識や体制が必要です。
社内に専門的な技術者がいない場合は、外部の専門家やパートナーの支援を活用するのも良い方法です。
技術面でのサポート体制を整えることが、スムーズな導入を実現するカギになります。
運用・セキュリティの配慮
VLMは入力に応じて様々な出力を生成できますが、その中には矛盾や攻撃的な内容、不適切な表現が含まれる可能性があります。
また、データの取り扱いやプライバシー保護など、セキュリティ面の配慮も欠かせません。 そのため、運用面でのルール作りやトラブル時の対応をあらかじめ考えておくことが大切です。
導入後も、生成した出力を必ず人の目でチェックする、不適切な内容が出力されると重大なリスクに繋がるような活用は避けるなど運用状況を見ながら改善や最適化を続ける姿勢が求められます。
VLMを導入する際の流れ
VLMを導入する流れは、以下のようなステップで進めるのがおすすめです。
1. 目的を明確にする
どのような業務課題を解決したいのか、目的をしっかり決めることが重要です。
2. 必要なデータの準備
VLMは画像やテキストを組み合わせた仕組みなので、必要なデータを整理し、準備します。
3. VLMの学習やカスタマイズ
必要に応じて、自社の業務に合うように学習モデルをカスタマイズします。
4. テストと評価
導入前にテストを行い、現場で使いやすいか、業務に合っているかを確認します。
5. 本格導入と運用
テスト結果をふまえて本格導入し、現場で活用をスタートします。運用後も必要に応じて調整を行い、改善していきます。
このように段階的に進めることで、VLMを無理なく現場に取り入れ、業務改善につなげることができます。
開発ベンダーでサポートを受けながら挿入もおすすめ
VLMの導入にあたっては、開発ベンダー(VLMの実装や運用を専門に支援する外部のパートナー)からサポートを受けるのも良い方法です。 無料相談バナー
技術的な知見や導入のノウハウを活かして、無駄のないスムーズな運用につなげることができます。

アラヤはVLMにおいて開発から導入まで一貫サポート
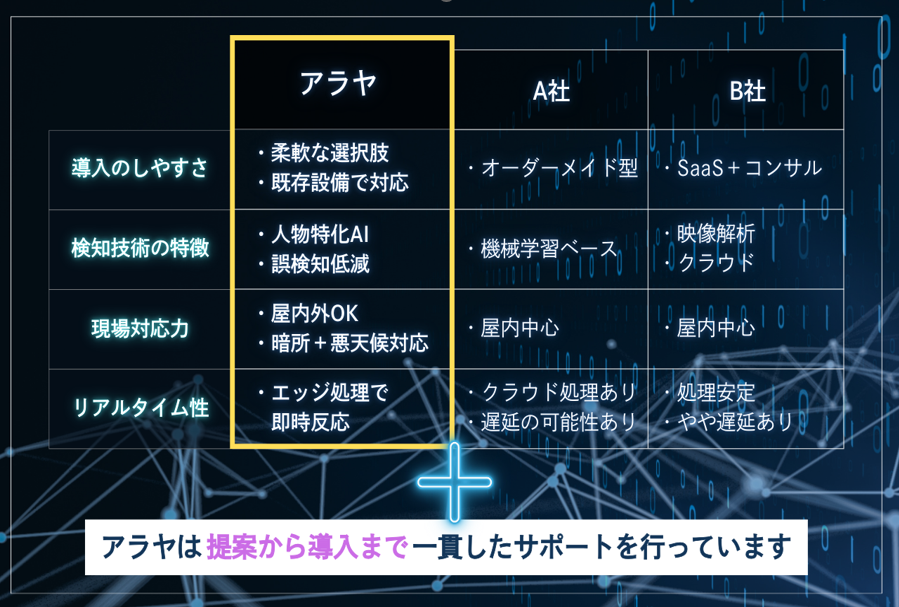
他社比較表
VLM(視覚言語モデル)の導入を考えている現場の方に向けて、アラヤでは企画から開発、導入、運用までを一貫してサポートしています。
業界や現場ごとに異なる課題に合わせて、最適なVLMのカスタマイズや運用設計をお手伝いします。
AIの知識がない方でもお任せください
専門的な知識が必要なVLM導入ですが、アラヤは豊富な実績を持つプロフェッショナルとして、初めての方でも安心して任せられる体制を整えています。
AIの活用で業務効率化や新しい価値を実現したい方は、まずは無料相談から始めてみてください。
まとめ
VLM(視覚言語モデル)は、画像とテキストを一緒に理解することで、業務の効率化や新しい価値を作るのに役立つ技術です。
ただし、導入にはデータや技術面での準備・理解が大切です。
アラヤでは、VLMの企画から開発・運用まで一貫してサポートしています。 無料相談バナー
初めての方も、まずは無料相談で自社に合った導入方法を見つけてみてください。
株式会社アラヤ
先端AIとニューロテックを基盤とするディープテックベンチャーです。ムーンショット型研究開発への参画をはじめ、企業・大学との共同研究実績を多数有し、現役研究者とエンジニアが一体となった研究支援を提供しています。大学・研究機関における持続可能な研究体制の構築と研究力強化に貢献してまいります。
主な事業概要
AIアルゴリズム開発(ディープラーニング・エッジAI・自律AI)、建設DXソリューション、研究現場の業務効率化支援(Research DX)など、基礎研究から社会実装まで一貫して手がけています。

