受託開発・お問い合わせ
受託開発・お問い合わせ
大規模言語モデルの進化とビジネスへの応用

RAGを使用したLLMでの独自データの活用
以下では、モデルの学習をすることなしに、LLMで独自データの活用が可能なRAG (Retrieval-Augmented Generation) について説明します。
RAGは、2020年に当時のFacebook社が発表した自然言語処理(NLP)モデルの性能向上手法です。事前学習したモデルの知識を、モデル外部に備えた知識データを用いて補完する手法です。RAGをLLMベースの質問応答システムに導入することで、モデルが外部に備えた最新かつ信頼性のある情報にアクセスでき、また、ユーザーがモデルの情報源にアクセスして正確性を確認することができます。これにより、モデルが生成する回答の情報が信頼できるものであることを保証できます。
RAGは、情報の取得(Retriever)、情報の組み合わせ・調整(Augmentation)、そしてテキスト生成(Generator)の3つの主要な要素で構成されます。
- Retriever:大量の情報から最も関連性の高いデータを効率的に抽出する役割を果たします。
- Argumentation:取得した情報とユーザーからのクエリを調和させ、適切な入力を形成します。
- Generator:入力に基づき、文脈に合わせたテキストを生成します。
RAGを用いることで、検索フェーズでは、ユーザーからの質問やプロンプトに関連した情報の断片を効率的に探し出し、検索内容に応じてモデルが事前学習したオープンなデータ、および、独自データのようなクローズドなデータを情報源として、回答を生成します。
実際にRAGの機能を実装するためには、LLMとは別に専用のライブラリ・フレームワークを使用します。このようなライブラリの一例として、下記があります。
- LangChain(https://www.langchain.com/)

言語モデルを活用したアプリケーション開発のフレームワークです。文脈認識機能や推論能力を持ち、モジュールコンポーネントを提供しています。言語モデル(LLM)と文章ソースとを繋ぐための様々なチェーンを使用することで簡単に利用でき、複雑なアプリケーションには既存のチェーンをカスタマイズするためのコンポーネントが利用できます。 - LlamaIndex(https://www.llamaindex.ai/)

LLMに専門的なデータやプライベートデータを取り込んでアプリケーションを構築するためのデータフレームワークです。LlamaIndexを用いることで、大量のデータで事前学習されたLLMに、分散保存された特定領域やプライベートなデータを取り入れることができます。 - haystack(https://haystack.deepset.ai/)

検索のさまざまなユースケースに対して、LLMを使用して強力で本番環境向けのパイプラインを構築するためのフレームワークです。RAGや質問応答、セマンティック検索など、Haystackの先進的なLLMやNLPモデルを利用して、ユーザーが自然言語でクエリを行えるカスタム検索体験を提供できます。
各ライブラリには提供機能の差異があります。ライブラリの選定には、それぞれのWEBサイト等を確認して必要な機能の有無を確認して下さい。また、下記の観点も考慮して下さい。
- 使いやすさ:アクセスが容易で、導入が簡単なフレームワークが望ましい。
- 柔軟性:独自の要件に合わせてカスタマイズが可能なフレームワークが効果的です。
- パフォーマンス:大量のデータの処理能力が確保されていること。
- 拡張性:将来の拡大や変更にも対応できるフレームワークが必要です。
- サポート:サポート体制や活発なコミュニティが存在するフレームワークを選択することで、トラブルシューティングや情報交換が容易になります。
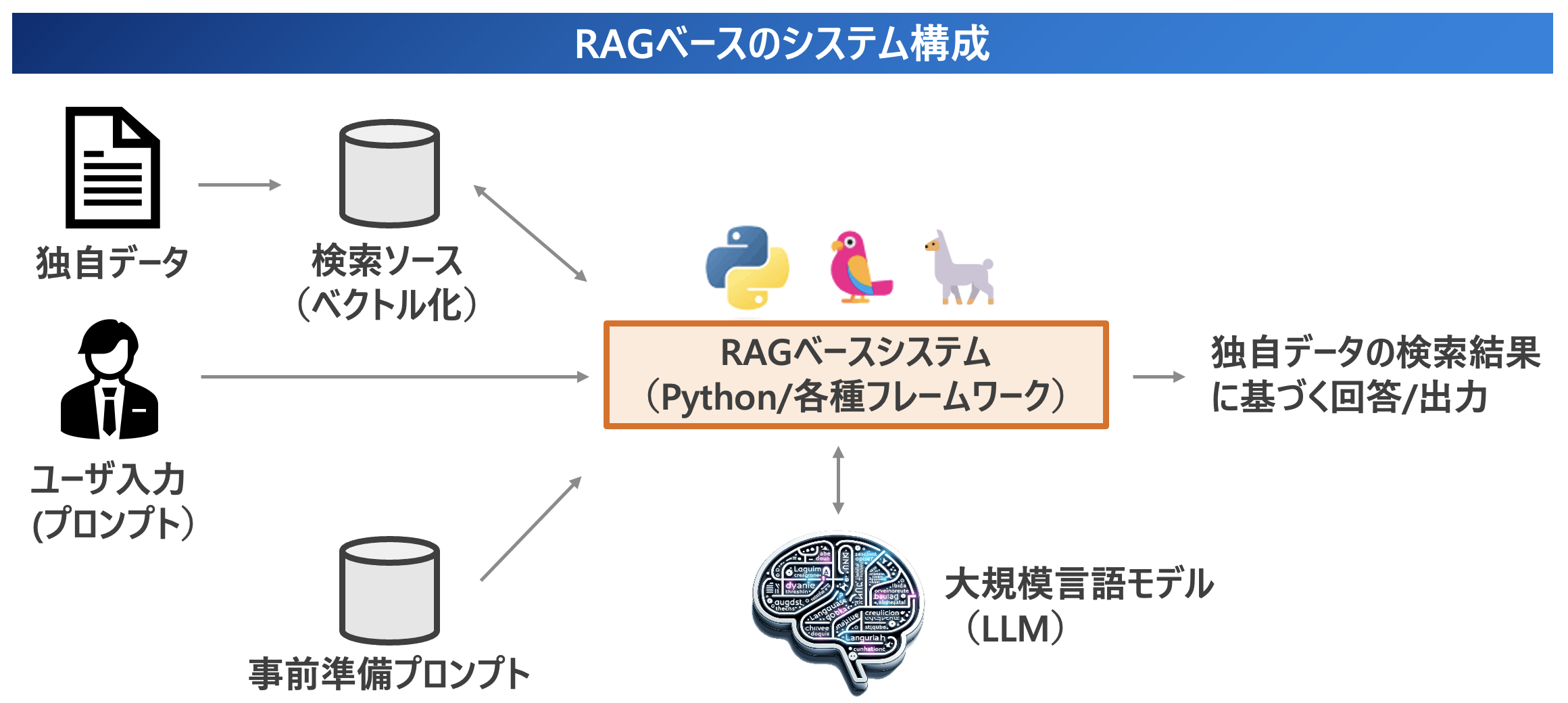
<画像>
下記にRAGベースの典型的なシステム構成を示します。アラヤでは Python をベースに LangChain や LlamaIndex を用いて、LLMで独自データを活用した様々なユースケースにおけるシステム構築に関するコンサルティング・提案・開発を行っています。