Contact Us
Contact Us
Evolution of large-scale language models and their application to business

USE OF PROPRIETARY DATA IN LLM WITH RAGS
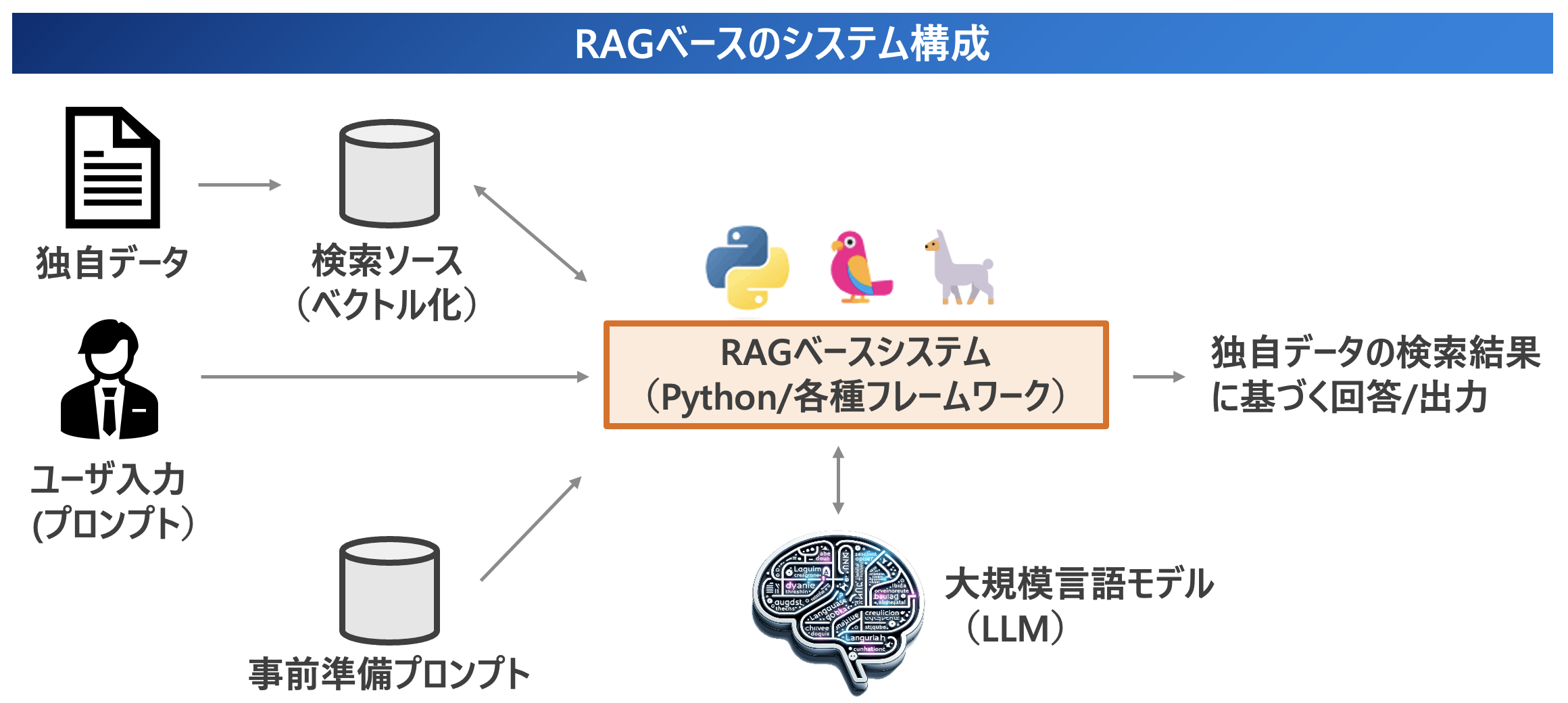
Below we describe Retrieval-Augmented Generation (RAG), which allows LLMs to leverage their own data without having to train models.
RAG is a method for improving the performance of natural language processing (NLP) models announced by then Facebook in 2020. By deploying RAG in LLM-based question answering systems, models can access up-to-date and reliable information from external sources, and users can access model sources to verify their accuracy. The model can access external, up-to-date, and reliable information. This can ensure that the information in the answers generated by the model is reliable.
The RAG consists of three main elements: Retrieval (Retriever), Combination and Adjustment (Augmentation), and Text Generation (Generator).
- Retriever: serves to efficiently extract the most relevant data from large amounts of information.
- Argumentation: Harmonize the retrieved information with the query from the user to form the appropriate input.
- Generator: Generates contextual text based on input.
With RAG, the search phase efficiently locates pieces of information relevant to the user's question or prompt, and generates answers using open data that the model has pre-trained, as well as closed data such as proprietary data, as sources of information, depending on the content of the search.
To actually implement the functionality of RAG, a dedicated library framework, separate from LLM, is used. An example of such a library is the following
- LangChain(in Japanese history)https://www.langchain.com/)

IT IS A FRAMEWORK FOR APPLICATION DEVELOPMENT THAT UTILIZES LANGUAGE MODELS. IT HAS CONTEXT-AWARENESS AND INFERENCE CAPABILITIES AND PROVIDES MODULAR COMPONENTS. IT IS EASY TO USE WITH A VARIETY OF CHAINS TO CONNECT LANGUAGE MODELS (LLMS) TO SENTENCE SOURCES, AND COMPONENTS ARE AVAILABLE TO CUSTOMIZE EXISTING CHAINS FOR MORE COMPLEX APPLICATIONS. - LlamaIndex(in Japanese history)https://www.llamaindex.ai/)

A data framework for building applications by incorporating specialized or private data into LLMs, LlamaIndex allows you to incorporate distributed, stored specific domain or private data into LLMs that have been pre-trained with large amounts of data. - haystack(in Japanese history)https://haystack.deepset.ai/)

A framework for building powerful, production-ready pipelines using LLMs for a variety of search use cases, including RAGs, question answering, and semantic search, using Haystack's advanced LLM and NLP models that allow users to query in natural language It can provide a custom search experience.
EACH LIBRARY OFFERS DIFFERENT FUNCTIONS. WHEN SELECTING A LIBRARY, PLEASE CHECK THE WEBSITE OF EACH LIBRARY TO SEE IF THE NECESSARY FUNCTIONS ARE AVAILABLE. ALSO, CONSIDER THE FOLLOWING POINTS
- Ease of use: A framework that is easily accessible and simple to implement is desirable.
- Flexibility: A framework that can be customized to meet unique requirements is effective.
- Performance: The ability to process large amounts of data is ensured.
- Scalability: The framework must be able to accommodate future expansion and changes.
- Support: Selecting a framework with a support structure and active community will facilitate troubleshooting and information exchange.