 受託開発・お問い合わせ
受託開発・お問い合わせ
「意識」の機能を持った汎用AIの実現(2):情報生成理論~架空の状況を「想像」する

人間が持つ「意識」とはどういうものか――アラヤでは、この問いに答えようと研究を続けています。私達は、意識に相当する人工物(AI)を作ることで、その実体に迫り、「汎用AI」の実現をしようとしています。
具体的にどのようなアプローチ方法を考えているかについて、代表取締役の金井良太が、4部構成で解説します。
・「意識」の機能を持った汎用AIの実現(1):概要と3つの仮説
・「意識」の機能を持った汎用AIの実現(2):情報生成理論~架空の状況を「想像」する(本記事)
・「意識」の機能を持った汎用AIの実現(3):グローバル・ワークスペース理論~脳のモジュール間の情報を橋渡しする
・「意識」の機能を持った汎用AIの実現(4):クオリアのメタ表現理論~新しいタスクに対処できるようになる
情報生成理論:架空の状況を「想像」する機能
1つ前の記事で、「意識」の機能を持った汎用AIを実現するための3つの仮説を紹介しました。この記事では情報生成理論(※1)について紹介します。
※1:R. Kanai et al., “Information generation as a functional basis of consciousness,” Neuroscience of Consciousness, Vol. 2019, Issue 1, 2019.
この理論が想定する意識の機能とは、「今・ここ」にある環境とは違う(反実仮想的な)情報を頭の中で作り出すことです。大雑把にいえば、現在とは異なる状況の「想像」に相当する能力です。意識にこの機能があるおかげで、例えば人が行動を起こす前や長期の計画を立てる時などに、あらかじめあれこれとシミュレーションできるのです。私達はこれを「反実仮想的シミュレーション」と呼んでいます。
この理論の核になる要素は、シミュレーションに使える現実世界のモデルが脳内にあるという仮定です。人間は感覚器や運動を通したやりとりを通じて自分を取り巻く世界のモデルを獲得し、このモデルを利用して、自分が行動すると何がどう変わるかを予測していると考えられます。つまりAIに意識の機能を持たせる第一歩は、世界をモデル化する能力の構築から始まるわけです。
世界をコンパクトに表現するGQN技術
世界をモデル化する上で重要なのは、できるだけコンパクトに表現することです。世界の状態を、画像や3次元モデルのような膨大な(高次元の)情報として記憶し再構成していたら、脳の限られた資源があっという間に使い果たされてしまいます。世界の本質的な特徴を捉えて、その振る舞いを可能な限り少ない情報量で再現することが重要です。
最近のディープラーニング技術の進展で、この条件を満たす手段の糸口が見えてきました。私達が注目する技術の一つが、グーグルの関連会社のディープマインドが2018年に発表した「Generative Query Network(GQN)」(※2)です。CGで表現した室内環境で、様々な形状や色彩の物体が配置された3次元空間の状態を、わずか256個(256次元)の変数で記述可能にしました。3次元モデルや画像を使って世界を表現する場合と比べると、かなり小さい情報量です。
※2:S. M. A. Eslami et al., “Neural scene representation and rendering,” Science, Vol. 360, 2018.
GQNがすごいのは、初めて見る場所でも、いくつかの角度からの見え方がわかれば、残り全てを補えることにあります。球や円錐などいくつかの物体が置かれた3次元CGの部屋の様子を2〜3箇所の視点から「撮影」し、その画像をGQNに入力するだけで、部屋中のあらゆる位置から見た画像を出力できます。実際、GQNが部屋の中を移動するかのように滑らかに視点を変えつつ描画する映像は、「正解」の画像と瓜二つで、多くのAI研究者を驚かせました。つまり、GQNは与えられた画像では物陰に隠れて見えない部分の風景も「想像」できるのです。
GQNが披露した離れ業の秘密は、何百万枚もの画像データを使った事前の学習にあります。壁や床の見栄え、物の色や形などを様々に変えたCGのシーンを大量に用意して学習させることで、GQNはシーンに共通する特徴を抽出し、画像に映った3次元環境の情報を余すところなく256個の変数に落とし込む術を身につけたわけです。
しかもGQNは、それぞれの変数が取りうる値の分布(確率密度関数)まで学んでおり、なおかつこの分布を、それぞれの画像を「撮影」した視点と紐付けることができます。この能力があるからこそ、いくつかのサンプル画像と視点の位置を指定すれば、確率的にその位置から見える可能性が高い画像を生み出すことができるのです。
脳の視覚野の仕組みはVAEの仕組みと合致する
GQNの学習にディープマインドが利用したのは、VAE(Variational AutoEncoder)(※3)と呼ばれるディープラーニング技術の一種です。私達は世界のモデルを構築する技術の候補としてVAEに期待をかけるとともに、人の脳内にはVAEと同様な学習の仕組みが組み込まれていると想定しています。脳内のこうしたメカニズムが、意識の発生に関与していると考えられます。
※3:D. P. Kingma et al., Auto-Encoding Variational Bayes, https://arxiv.org/abs/1312.6114
VAEは、異常検知などに利用されるディープラーニング技術であるAE(AutoEncoder)をもとにした手法です。画像を入力すると、エンコーダにより画像データを圧縮(変数の値を抽出)し、さらにそこからデコーダにより元の画像を復元するという仕組みで学習させます。エンコーダが出力する変数は潜在変数と呼ばれ、画像を表現する上で本質的な情報とみなせます。
※詳しく書くと、AEが元の画像の潜在変数を求める手法であるのに対し、画像の潜在変数が従う確率分布の平均や分散を推定する手法がVAEです。ちなみにGQNが用いたのはVAEを発展させた条件付きVAE(Conditional VAE)という手法で、現在の環境のサンプル画像数枚と、元の画像の視点の位置という条件も加えた上で、元の画像の潜在変数の確率分布を推定するように学習させています。
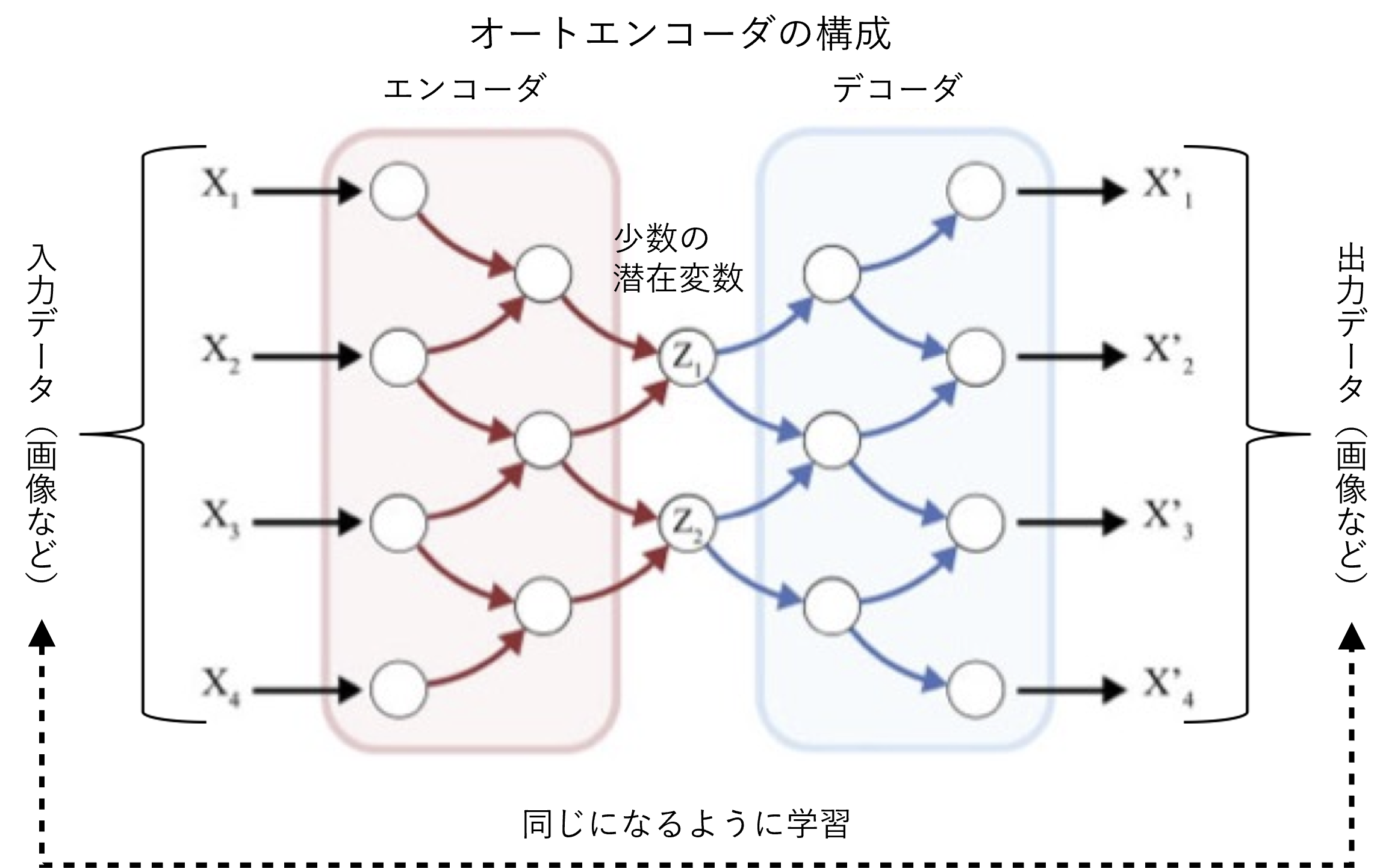
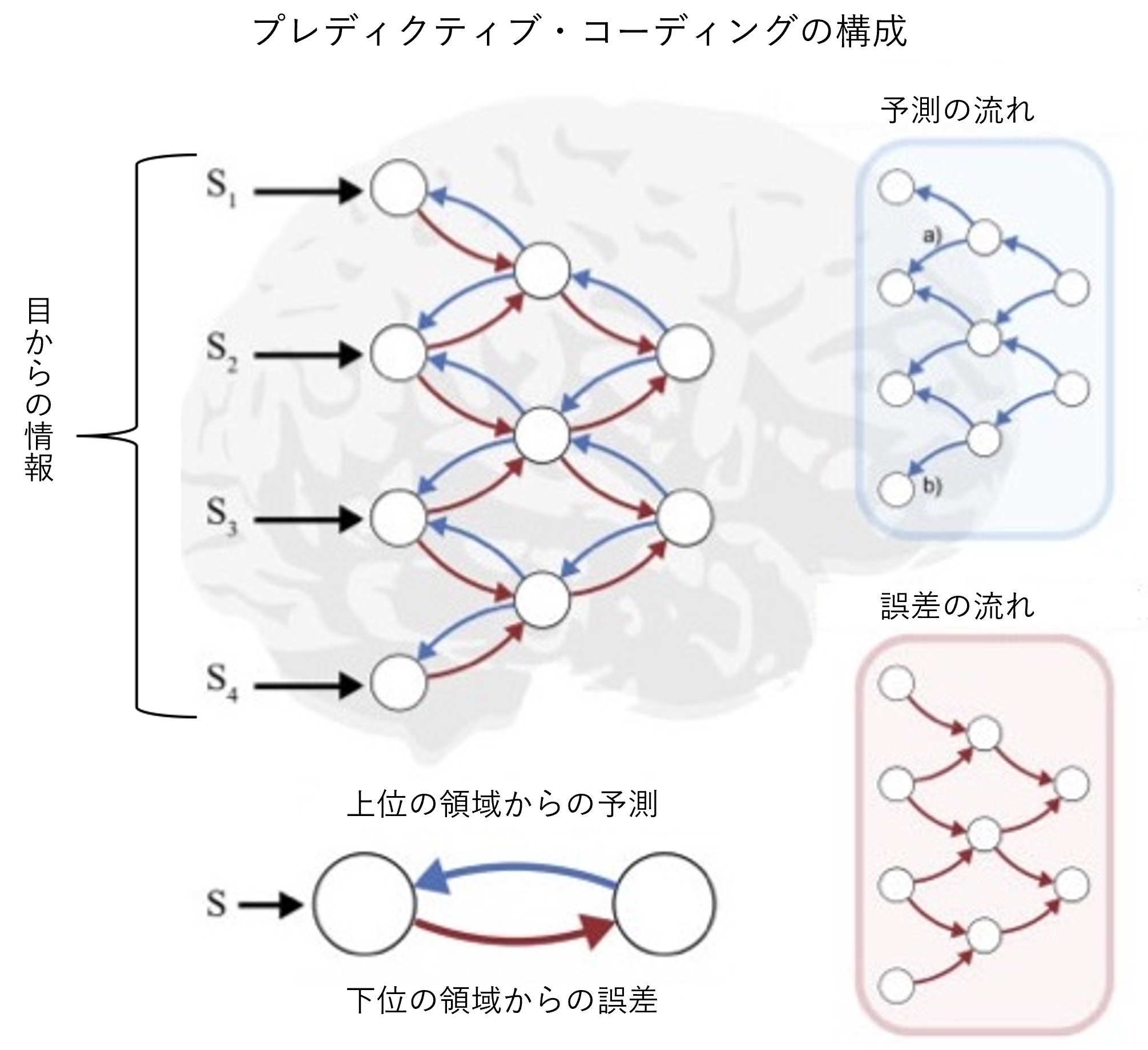
このようなAEのエンコーダとデコーダの関係に類似した仕組みが、脳の視覚野などの理論として提案されています。「プレディクティブ・コーディング」と呼ばれる仮説です。脳の視覚野は、目から送られた「生の」情報を扱う下位の領域から、物体の認識など高度な処理を担う上位の領域に向けて、何層もの階層構造になっています。この階層を上がるほど、膨大な情報量の画像から冗長な部分が削ぎ落とされ、少量の本質的な情報が残っていくと見られます。このような一連の処理の中で、より正確な情報を抽出するための仕組みが、プレディクティブ・コーディング(※4)です。
※4:R. P. N. Rao et al., “Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects,” Nature Neuroscience, vol. 2, no.1, January1999.
視覚野の各層の間には、(1)上位から下位に向けて信号を伝える経路と、(2)その逆に下位から上位に向かう経路が存在します。プレディクティブ・コーディングの理論では、より上位にある領域は手元の情報を基に下位の領域で処理中の画像情報を予測して(1)の経路で順次伝えていくと考えます。一方、より下位の領域は受け取った予測と実際の情報の差分(誤差)に相当する信号を(2)の経路で上位に送ります。これを受け取った上位の領域は、誤差を修正することでより正確な予測が可能になるわけです。このような予測と修正の繰り返しにより、脳は世界を正しく認識できるというのが、プレディクティブ・コーディングの骨子です。
私達は、プレディクティブ・コーディングにおける(1)上位から下位に向かう経路の働きはAEのデコーダ、(2)下位から上位への経路の役割はAEのエンコーダと符合すると見ています。
世界モデルをロボットに組み込むことに成功
こうした仮説に基づき、アラヤではVAEやプレディクティブ・コーディングを応用して世界モデルを構築・利用するための技術を開発しています。実用化までに時間を要する基礎研究の色合いが濃いため、文部科学省傘下の科学技術振興機構(JST)や経済産業省系の新エネルギー・産業技術総合開発機構(NEDO)が推進するプロジェクトの枠内で国から予算の支援を受けて取り組んでいます。
例えばJSTの戦略的創造研究推進事業(CREST)の一環では、ユーザーである人間が「意識がある」という感覚を抱くような人工知能の開発を目指してきました(※5)。その成果として2021年3月には、簡単なデモを披露するまでに至っています。カメラを搭載したロボットを利用して、置き忘れた物を探す人を手助けするシステムです。ユーザーからの問い合わせを受けたAIは、自身が場所を把握している時には物の位置を答え、そうでない場合はロボットに探しに行かせることができます。
※5:金井良太, 人間と調和した創造的協働を実現する知的情報処理システムの構築 2019年度実績報告書、https://www.jst.go.jp/kisoken/crest/evaluation/nenpou/r01/JST_1111083_15656376_2019_PYR.pdf
このシステムの特徴は、ロボットが「好奇心」に従って探す箇所を選ぶことです。前述のGQNでは、世界モデルのどの部分が確かでどの部分は不正確かを数値で表せます。このロボットも同様な仕組みを備えており、世界モデルの確かな部分には見向きもせず、不確かな部分を重点的に調べます。つまり、知らないところに興味を惹かれる、擬似的な「好奇心」が備わっているのです。これによって効率的に探し物を見つけることができます。
まずは特定の業務向けに実用化し、最終的に「人間レベル」を目指す
究極の目標である汎用AIへは遥かな道のりです。先述のGQNが獲得できる世界モデルは、現時点では、対象がCGの環境に限られるうえ、行動に対する環境の変化(ダイナミクス)も表現できません。最近では、世界の空間的・時間的なモデルを獲得し、このモデルを使ってロボットに行動の指針(ポリシー)を学ばせる研究もあるものの、やはりCGが作り出す単純な世界を相手にするのが普通です(※6)。アラヤのデモ用ロボットも、把握できる環境の範囲はごく限られ、人の持つ広範な能力には遠く及びません。
※6:例えばD. Ha et al., “World Models,” https://arxiv.org/abs/1803.10122
ただし、人のレベルに追いつくまで実用化を待つ必要はありません。特定の業務向けであれば、世界モデルを組み込んだAIを近い将来に利用できる可能性があります。こうした小規模な用途で有用性を確かめることは、相当な開発コストを要する「人間レベル」の取り組みに踏み出す決断にもつながります。
アラヤが当初の応用先として想定するのは、送電線などの点検に使うドローンが、自らの好奇心に従って重点的に確認する箇所を選ぶことで検査の効率を高めるといった使い方です。先ほどのロボットの技術を応用すれば、そう遠くない将来に実現できると考えています。
■続きはこちら
・「意識」の機能を持った汎用AIの実現(1):概要と3つの仮説
・「意識」の機能を持った汎用AIの実現(2):情報生成理論~架空の状況を「想像」する(本記事)
・「意識」の機能を持った汎用AIの実現(3):グローバル・ワークスペース理論~脳のモジュール間の情報を橋渡しする(次の記事)
・「意識」の機能を持った汎用AIの実現(4):クオリアのメタ表現理論~新しいタスクに対処できるようになる

