 受託開発・お問い合わせ
受託開発・お問い合わせ
「意識」の機能を持った汎用AIの実現(3):グローバル・ワークスペース理論~脳のモジュール間の情報を橋渡しする

人間が持つ「意識」とはどういうものか――アラヤでは、この問いに答えようと研究を続けています。私達は、意識に相当する人工物(AI)を作ることで、その実体に迫り、「汎用AI」の実現をしようとしています。
具体的にどのようなアプローチ方法を考えているかについて、代表取締役の金井良太が、4部構成で解説します。
・「意識」の機能を持った汎用AIの実現(1):概要と3つの仮説
・「意識」の機能を持った汎用AIの実現(2):情報生成理論~架空の状況を「想像」する
・「意識」の機能を持った汎用AIの実現(3):グローバル・ワークスペース理論~脳のモジュール間の情報を橋渡しする(本記事)
・「意識」の機能を持った汎用AIの実現(4):クオリアのメタ表現理論~新しいタスクに対処できるようになる
脳のモジュール間の情報を「グローバル・ワークスペース」で橋渡しする
私達が想定する意識の機能は、世界モデルを使って架空の状況を想像する能力だけではありません。汎用AIの実現に役立つ意識の機能の2つ目に挙げるのは、「脳内の複数の機能を共通の潜在空間を介して接続する能力」です。意識の役割を説明する「グローバル・ワークスペース理論」と呼ばれる仮説に基づきます。
グローバル・ワークスペース理論が前提にするのは、人の脳は視覚や聴覚、運動や言語など、特定の機能に特化したいくつものモジュールから構成されるとの仮説です。意識は、これらのモジュール間で情報を橋渡しする機能をするというのが理論の骨子といえます。人が実世界の中で的確に行動できるのは、意識が複数の専用モジュールを巧妙に連携させているおかげと考えます。その際に、異なるモジュールの間の情報を取り持つ場が「グローバル・ワークスペース」です。
グローバル・ワークスペース理論は1980年代に提唱され、多くの実験結果に支持されてきました(※1)。コンピュータ・シミュレーションなどを通して、どのような神経回路がグローバル・ワークスペースを形作るかを探る研究も進んでいます(※2)。モントリオール大学のベンジオ教授が打ち出した「事前状態としての意識(Consciousness Prior)」の概念もグローバル・ワークスペース理論に基づくものです(※3)。
※1:B. J. Baars, “The conscious access hypothesis: origins and recent evidence,” TRENDS in Cognitive Sciences, Vol.6, No.1, January 2002.
※2:G. A. Mashour et al., “Conscious Processing and the Global Neuronal Workspace Hypothesis,” Neuron, 105, March 4, 2020.
※3:Y. Bengio, “The Consciousness Prior,” https://arxiv.org/abs/1709.08568
グローバル・ワークスペースを利用するAIをディープラーニングの組合せで実現
これらの先行研究に続いてアラヤが取り組むのは、グローバル・ワークスペースを利用するAI技術の開発です。私(金井)とフランスの研究機関CerCo(Centre de Recherche Cerveau & Cognition)の研究ディレクターとの共著で、構想を記した論文を2020年12月に発表しました(※4)。その中にも書かれていますが、実現に必要な要素技術は、個別には既に存在していると考えています。
※4:R. VanRullen et al., “Deep Learning and the Global Workspace Theory,” https://arxiv.org/abs/2012.10390
基本的な発想は、特定の機能のモジュールをディープラーニングで学習させたニューラルネットワークで実現し、その間をつなぐ機構をグローバル・ワークスペースとして実装するというものです。ディープラーニングは、画像認識や音声認識、言語処理など多くの分野で人を凌ぐ能力を達成しつつあり、その成果を活用するのはごく自然な発想です。AIが多様なニューラルネットワークを自由に組み合わせて活用できれば、対処できるタスクは一挙に広がり、人のような汎用性に大きく近づきます。
問題は、異なるニューラルネットワークの間で、どのように情報を共有するかです。例えば目の前の光景を視覚用ニューラルネットワークが認識した場合、聴覚用ニューラルネットワークで捉えた音がどの物体のものかを推定したり、次に取る行動を制御用ニューラルネットワークで判断したりするには、視覚用ニューラルネットワークの情報を他のニューラルネットワークが活用できる形で伝える必要があります。ところが、一般にニューラルネットワークの入出力は用途ごとにバラバラで、情報の共有には必ずしも適していません。
異なるニューラルネットワークの情報共有は、潜在変数を相互に翻訳することで実現する
異なるニューラルネットワークの間での情報共有の方法に対する私達の答えは、それぞれのニューラルネットワークに固有の潜在変数を、互いに翻訳し合う仕組みです。
画像や音声を認識するニューラルネットワークは、膨大な情報を含む個々のデータを、それらの特徴を凝縮した少数の(低次元の)潜在変数の値に落とし込みます。元のデータの特徴を詰め込んだ潜在変数は、異なるデータを区別するのに十分な情報を保持しています。ニューラルネットワークが画像の分類や音声の聞き分けを適切に処理できるのは、潜在変数のおかげといえます。
ただし、各々のニューラルネットワークが用いる潜在変数の間に互換性は全くありません。そこで潜在変数の間の変換機構を、グローバル・ワークスペースとして実装しようというわけです。
潜在変数を変換する技術の「種」は既にあります。一例は、画像を入力すると内容を説明する文章を出力するニューラルネットワークです。いわば画像を文章に「翻訳」する技術です。こうした技術は、機械翻訳に使うニューラルネットワークを基に開発されており、画像を潜在変数に変換するエンコーダと、潜在変数を利用して文章を生成するデコーダを組み合わせた構成をとるのが一般的です(※5)。このニューラルネットワークを画像と文章を対にした大量のデータで学習させれば、カメラが撮影した光景を、人が書いたような文で描写できるようになるのです。同様にして、どのようなニューラルネットワークの潜在変数であっても、別のニューラルネットワークの潜在変数に変換するのは、理論上は可能と見られます。
※5:S. Li et al., “Visual to Text: Survey of Image and Video Captioning,”IEEE Transactions on Emerging Topics in Computational Intelligence, January 2019.
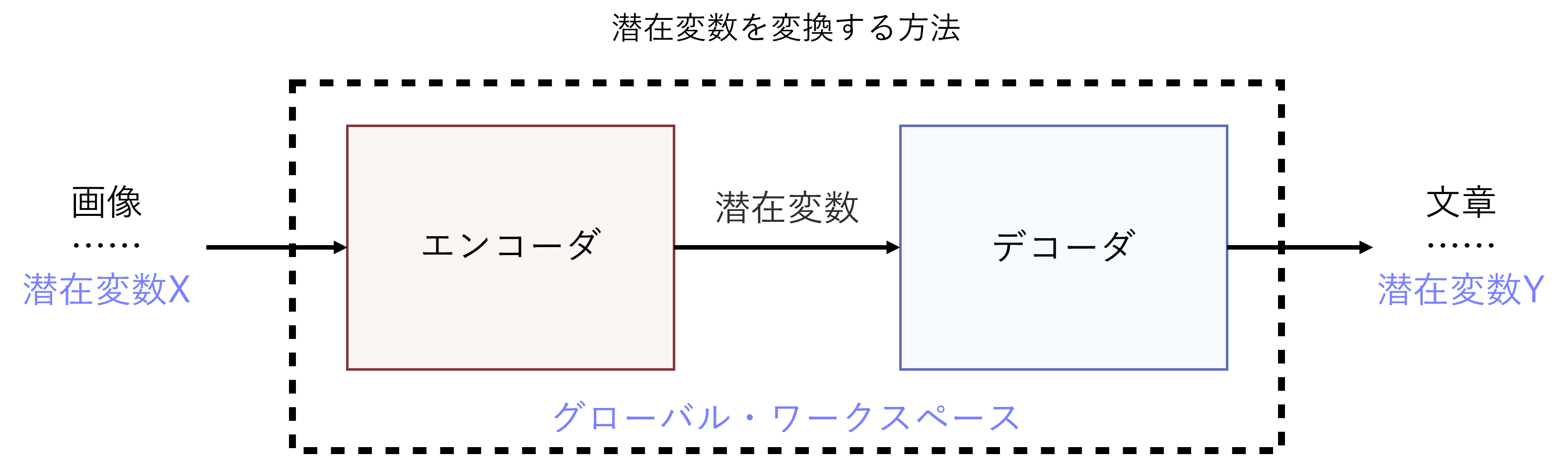
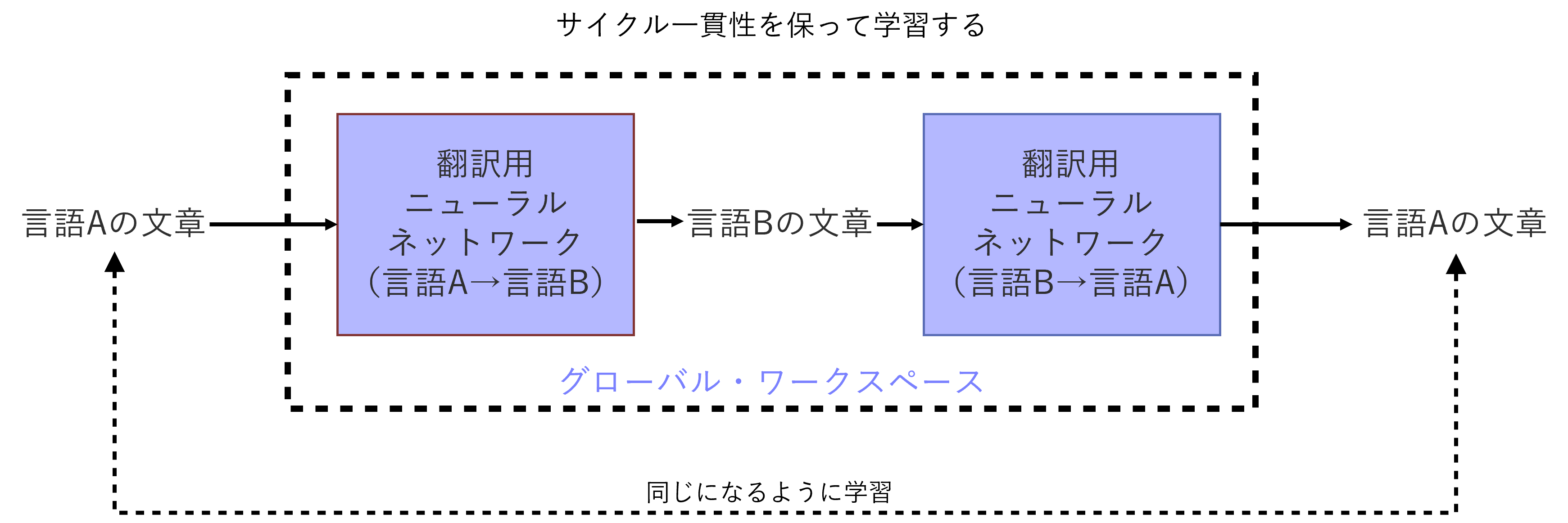
前述の2020年12月に発表した論文では、グローバル・ワークスペースに相当するニューラルネットワークが、潜在変数の変換方法を自ら学習する手段も提案しています。人が正解を示さなくても学習が可能な、いわゆる「教師なし学習」を用いる想定です。
学習の基準として頼りにするのは「サイクル一貫性」と呼ぶ原則です。例えば、ある言語Aの文章を別の言語Bに翻訳した後、元の言語Aに翻訳し直したときに、同じ文章に戻るかどうかを目安として学習させます。この方法を使って、精度の高い翻訳用ニューラルネットワークを開発できることがこれまでの研究で示されています(※6)。異なる潜在変数の間の翻訳にも、同様な手段が使えそうです。
※6:G. Lample et al., “Unsupervised Machine Translation Using Monolingual Corpora Only,” https://arxiv.org/abs/1711.00043
グローバル・ワークスペースが動作する仕組み
こうした発想をベースに、前述の論文ではグローバル・ワークスペースのあるべき姿や動作の仕組みの青写真を描いています。グローバル・ワークスペースには、視覚や聴覚といった外部の環境を認識するモジュール、発話や動きといった能動的な行動を生成するモジュールなど、数多くのニューラルネットワークが接続されます。グローバル・ワークスペースは、その全ての組み合わせに対して潜在変数の値を相互に変換・伝達する機能を備える想定です。
今、この構成を採るAIを搭載したロボットが、部屋の中で物を探しているとしましょう。グローバル・ワークスペースには、視覚や聴覚を担当するモジュールから時々刻々と変化する部屋の状況が伝えられます。グローバル・ワークスペースは、それらの情報をAIが備える全てのモジュールの潜在変数の値に逐一変換し、例えば運動モジュールに情報が伝わることで部屋の探索ができます。一方で、ロボットが部屋の状況をいちいち声に出して説明する必要が無ければ、発話モジュールはグローバル・ワークスペースから分離しておけば情報は送られません。
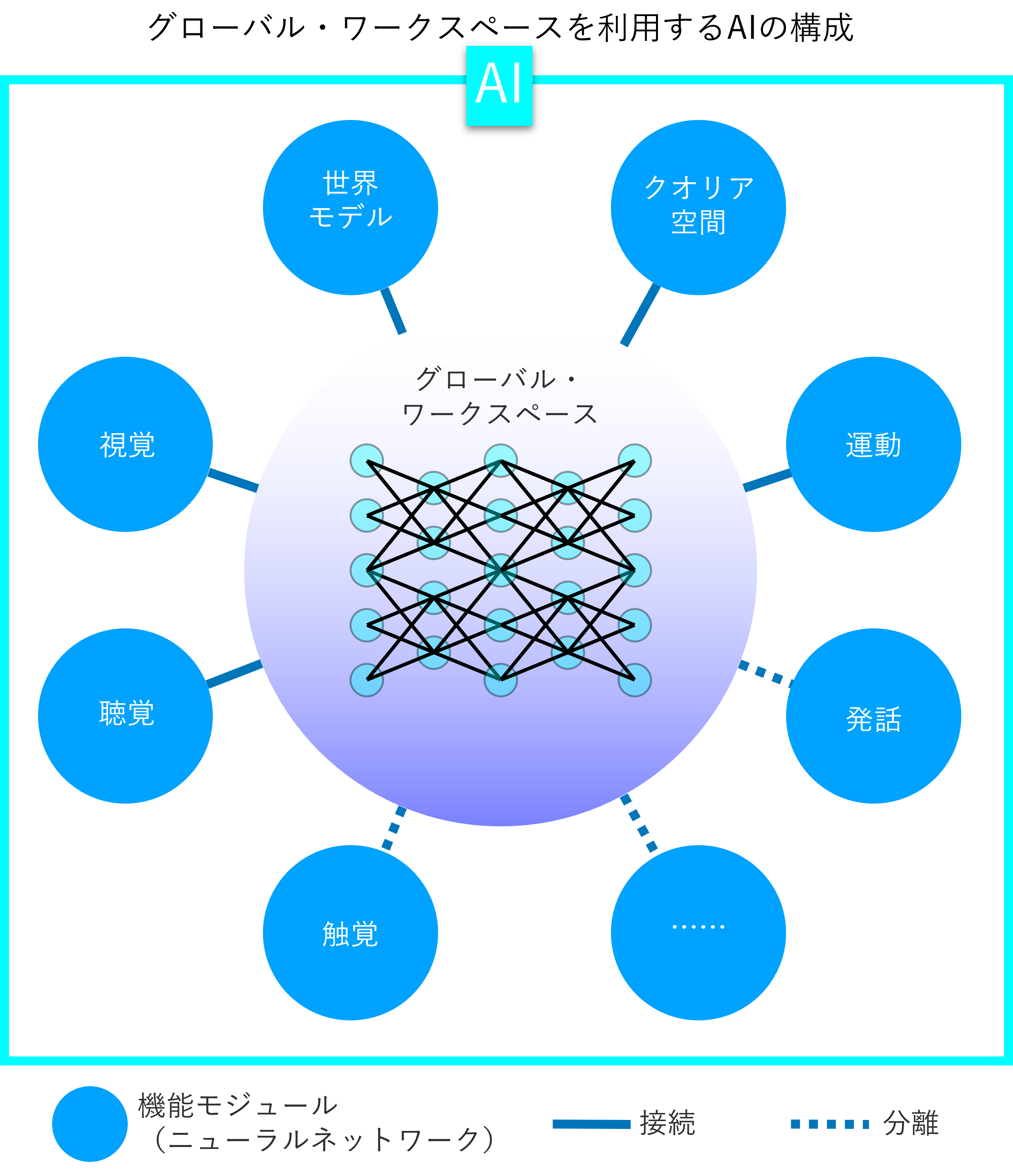
その時々で各モジュールが発する情報は、常にグローバル・ワークスペースに到達するわけではありません。グローバル・ワークスペースが取り上げて他のモジュールに変換・伝達される潜在変数、いわば「意識の内容」に相当する情報は、現在実行中のタスクに応じてトップダウンに決まります。グローバル・ワークスペースには実行中のタスク自体の潜在表現があり、それとマッチするモジュールの情報が選ばれる格好です。
このマッチングには、いわゆる「注意(アテンション)」の仕組みを使えると見ています。アテンションは機械翻訳などで利用されるニューラルネットワークの機構で、現在処理中の内容に関連した情報を効果的に処理に取り込むことができます。
グローバル・ワークスペースが取り上げて各モジュールに送る情報が、モジュールからの信号に応じてボトムアップに決まるケースもあります。例えば、物探しの途中でロボットの目の前にいきなり子供が飛び出してきたような場合です。こうした急を要する情報は、即座にグローバル・ワークスペースにアップされ、それを受けた運動モジュールが回避動作を発動するなど、素早い行動が取られます。ワークスペースに急遽、発話モジュールが接続されて、「危ない!」といった音声を発することも可能です。
グローバル・ワークスペースの実装は、私達が意識の第一の機能として挙げた世界モデルに基づく情報生成とも関係しています。端的にいえば、世界モデルはグローバル・ワークスペースにつながるモジュールの一つとして位置付けることができます。世界モデルを使った反実仮想的なシミュレーションが、ワークスペース上の情報として意識に上るイメージです。
■続きはこちら
・「意識」の機能を持った汎用AIの実現(1):概要と3つの仮説
・「意識」の機能を持った汎用AIの実現(2):情報生成理論~架空の状況を「想像」する
・「意識」の機能を持った汎用AIの実現(3):グローバル・ワークスペース理論~脳のモジュール間の情報を橋渡しする(本記事)
・「意識」の機能を持った汎用AIの実現(4):クオリアのメタ表現理論~新しいタスクに対処できるようになる(次の記事)

