 Contact Us
Contact Us
FIVE THINGS TO CONSIDER WHEN IMPLEMENTING EDGE AI

IN RECENT YEARS, "EDGE AI", THE IMPLEMENTATION OF AI MODELS ON EDGE DEVICES USED IN THE FIELD, HAS BEEN ATTRACTING ATTENTION AND ITS USE CASES ARE INCREASING. WE ARE ALSO RECEIVING AN INCREASING NUMBER OF REQUESTS FROM OUR CLIENTS FOR CONSULTING AND IMPLEMENTATION OF EDGE AI.
BASED ON OUR PRACTICAL EXPERIENCE OF EDGE AI DEVELOPMENT AND IMPLEMENTATION, THIS TWO-PART SERIES, INCLUDING THIS ARTICLE, WILL PROVIDE AN OVERVIEW OF THE TRENDS IN EDGE AI TECHNOLOGY AND THE POINTS TO CONSIDER WHEN IMPLEMENTING IT.
(1) The latest trends in edge AI technology
(2) Five points to consider when implementing edge AI (this article)

KEY POINTS WHEN IMPLEMENTING EDGE AI 1: CONSIDER THE ADVANTAGES AND DISADVANTAGES OF EDGE AI
There are actually advantages as well as disadvantages in implementing edge AI. Therefore, the first point to consider is to consider both the advantages and disadvantages of implementing edge AI, and only implement it on edge devices when the advantages outweigh the disadvantages.
ADVANTAGES AND DISADVANTAGES OF EDGE AI
The benefits of edge AI include (1) real-time, (2) low latency, (3) privacy protection, and (4) reduced communication costs.
On the other hand, the disadvantages of edge AI are (1) more complex model management, (2) initial investment requirements, and (3) increased hardware operation and maintenance.

DECISION-MAKING PROCESS ON WHETHER TO EMBRACE EDGE AI
The advantages and disadvantages of Edge AI and how decisions should be made in development practice.
For example, most of the use cases for the field, such as manufacturing and construction, should be done on the edge rather than in the cloud. For manufacturing use cases in particular, it is likely that as little information as possible will be sent to the cloud, or if it is, it will be limited to statistical data such as anomaly rates, in order to protect privacy and confidential information.
Embedded edge devices vs workstations
However, the question of whether to embed in an embedded edge device (e.g. NVIDIA Jetson) or whether to install a workstation or gaming PC to perform inference at the edge is a separate issue. In this regard, it is necessary to consider both "whether the requirements can be fulfilled by embedding in edge devices (edge AI )" and "the significance of embedding ".
WITH REGARD TO THE FORMER QUESTION, "CAN THE REQUIREMENTS BE ACHIEVED BY EMBEDDING IN AN EDGE DEVICE?", GENERALLY SPEAKING, CONVERTING WORKSTATIONS TO EDGE AI WILL LIMIT COMPUTING RESOURCES AND SLOW DOWN THE PROCESSING SPEED (OUR MODEL LIGHTENING TECHNIQUES TO REDUCE THE SPEED LOSS ARE DESCRIBED BELOW). IT IS IMPORTANT TO CONSIDER WHETHER THIS IS ACCEPTABLE FOR YOUR REQUIREMENTS. IN SOME CASES, THE COMMUNICATION TIME MAY BE THE BOTTLENECK IN THE OVERALL SYSTEM PROCESSING TIME, IN WHICH CASE THE REDUCTION IN PROCESSING SPEED DUE TO EDGE AI MAY NOT BE AN ISSUE.
As for the latter, we consider, for example, the scale of the expected deployment. As the scale of deployment increases (e.g. the number of factories and shops to be deployed), the significance of reducing hardware procurement costs through the use of edge devices increases.
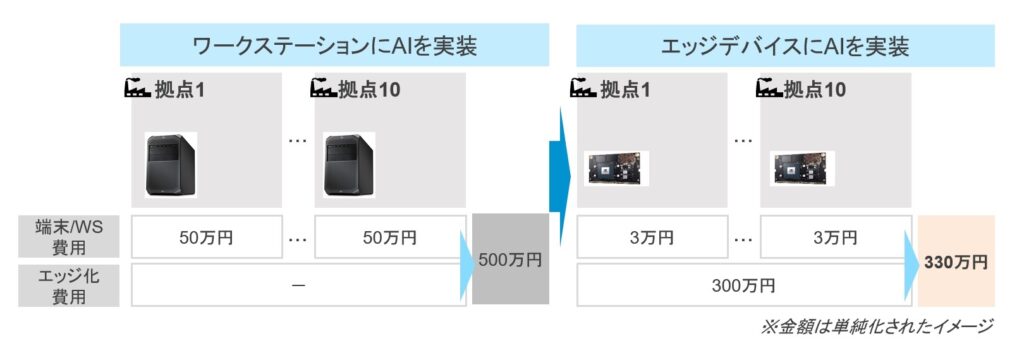
EDGE AI IMPLEMENTATION POINT 2: CONSIDER THE TRADE-OFF BETWEEN SPEED AND ACCURACY
AI models on edge devices often need to be lightweight in order to meet performance requirements. In general, lightweight AI models are known to improve inference speed, but degrade accuracy. In fact, MobileNet V3/V2 is an AI model that can improve speed by reducing its weight, but accuracy degrades as latency decreases, and the accuracy degradation is particularly pronounced at low latencies (*1).
Therefore, it is important to look at the correspondence between the speed and accuracy of edge AI, and determine the performance requirements of "what speed is required and what level of accuracy degradation is acceptable", along with feasibility.
*1: A. Howard et al., "Searching for MobileNetV3," 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019, pp. 1314-1324, doi: 10.1109/ICCV.2019.00140.
KEY POINT 3 WHEN IMPLEMENTING EDGE AI: BENCHMARKING ON EDGE DEVICES
THERE ARE MANY DIFFERENT COMBINATIONS OF AI MODELS AND HARDWARE THAT CAN BE USED TO IMPLEMENT EDGE AI. FOR EXAMPLE, THERE ARE AI MODELS WITH FEW PARAMETERS AND HIGH INFERENCE EFFICIENCY, AND AI MODELS WITH MANY PARAMETERS AND HIGH ACCURACY BUT LOW INFERENCE EFFICIENCY.
There is a wide choice of hardware, some from NVIDIA, some with AI accelerators, and many that take time to set up. Each has its own limitations and speed-up know-how. It is therefore necessary to benchmark each hardware optimisation.
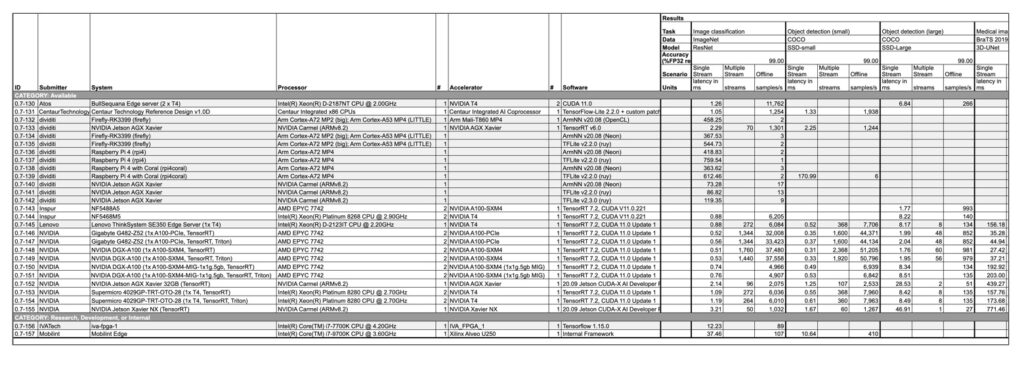
One solution is to use publicly available benchmarks such as MLPerf (*2), developed and published by a number of companies including Intel, Google, NVIDIA and smartphone manufacturers. MLPerf is developed and published by a number of companies, including Intel, Google, NVIDIA and smartphone manufacturers, and contains benchmarks for a variety of processors, accelerators and other devices. The benchmarks are based on a variety of processors, accelerators, and other devices, and include details of the hardware and software requirements and target tasks (image classification, object detection, speech recognition, natural language processing, etc.). However, as the number of datasets and AI models is limited, we believe it is better to use it as a reference.
2: https://mlcommons.org/en/
EDGE AI IMPLEMENTATION POINT 4: CONSIDER WHETHER THE AI MODEL CAN BE IMPLEMENTED IN EDGE DEVICES
WHEN TRAINING AI MODELS FOR EDGE DEVICES, IT IS NECESSARY TO TAKE INTO ACCOUNT THE TYPES OF OPERATIONS AND LAYERS SUPPORTED BY THE DEVICE.
In the first case, it is not possible to compile an AI model for edge devices.
Specifically, there are some network architectures, operations or layers - especially custom layers - that cannot be transformed. In such cases, it is necessary to substitute other layers or, if possible, to define custom layers separately.
The second case to consider is when the compilation is possible but not accelerated by the device. Specifically, some hardware operations/layers do not support acceleration and therefore do not run fast on edge devices.
For example, in Coral, if there is an unsupported operation in the middle of a neural network model, the CPU executes the subsequent operations (*3), and thus high-speed processing becomes impossible. (Coral's operations are shown in the figure below.)
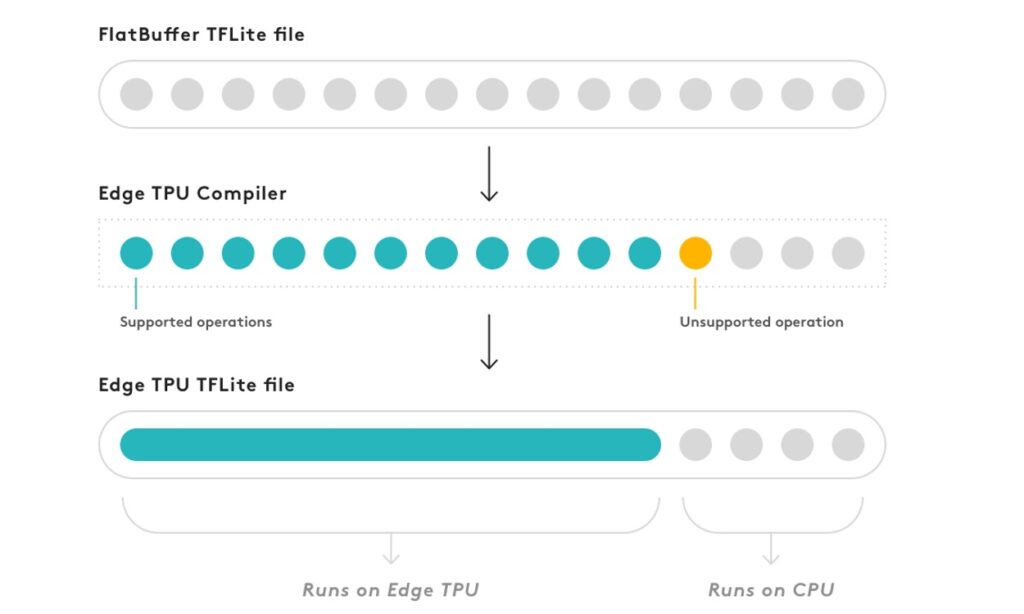
3: https://coral.ai/docs/edgetpu/models-intro/#compiling
KEY POINT 5 WHEN IMPLEMENTING EDGE AI: CONSIDER MAKING YOUR NEURAL NETWORK LIGHTWEIGHT
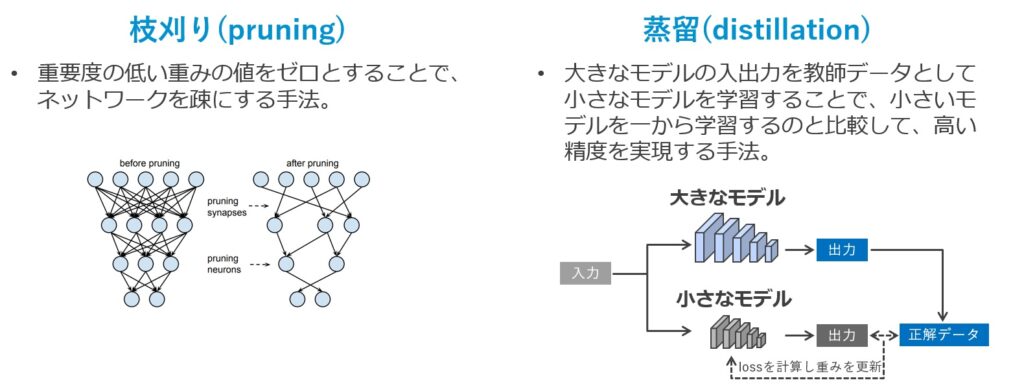
In general, the speed-up of neural networks by weight reduction is often accompanied by accuracy degradation, but with good weight reduction the accuracy degradation can be kept small. Typical methods of model weight reduction are pruning, distillation and quantization.
https://papers.nips.cc/paper/2015/file/ae0eb3eed39d2bcef4622b2499a05fe6-Paper.pdf
Branch trimming is a technique to make the network sparse by setting the less important weight values to zero. By pruning the branches, it is possible to reduce the number of operations in the neural network, making the model lighter and faster.
Distillation is a technique in which the results of training a large model are used to train a small model using the results of training a large model as teacher data. Compared to training a small model from scratch, this method can achieve a higher accuracy.
Quantization is a method of replacing floating point operations with integer operations to reduce the weight of a model, and is already common in many devices and tools. For example, Intel's OpenVINO neural network compilation tool, Google's TensorFlow Lite optimisation framework and NVIDIA's TensorRT neural network inference optimisation tool support 8-bit quantization with little loss of accuracy. TensorFlow Lite, an optimisation framework from Google, and TensorRT, a neural network optimisation tool from NVIDIA, support 8-bit quantization with little loss of accuracy. However, simple quantization below 8 bits (post-training quantization) often leads to significant accuracy degradation and requires a combination of specialised methods such as quantization aware training and calibration to reduce accuracy degradation. It is therefore important to use a combination of specialised methods, such as quantization aware training and calibration, to reduce the accuracy degradation.
HOW TO CHOOSE AN EDGE AI DEVELOPMENT VENDOR
THERE WILL BE TIMES WHEN USERS WILL NEED TO USE EXTERNAL VENDORS TO DEVELOP EDGE AI. IN ORDER TO SELECT AN EXTERNAL VENDOR, IT IS IMPORTANT TO CONSIDER THE FOLLOWING ASPECTS RELATED TO THE FIVE POINTS MENTIONED ABOVE.
Know-how in model weight reduction development
As mentioned in point 5, there are various methods for weight reduction, and it is not an issue that can be solved simply by applying one method. It is desirable to have a vendor who is familiar with the various methods and who can establish their own development methods and promote development efficiently and effectively.
Expertise in the use of hardware
AS MENTIONED IN POINTS 3 AND 4, EDGE AI DEVELOPMENT NEEDS TO BE CONSIDERED AS A SET WITH HARDWARE (EDGE DEVICES). IT IS NECESSARY TO SELECT AN APPROPRIATE DEVICE ACCORDING TO THE REQUIREMENTS AND TO DESIGN A DEVELOPMENT METHODOLOGY ACCORDING TO THE SELECTED DEVICE, AND IT IS DESIRABLE TO HAVE A VENDOR WITH THE KNOW-HOW TO DO SO.
Ability to make proposals that match business requirements
AS MENTIONED IN POINTS 1 AND 2, THE DEVELOPMENT OF EDGE AI INVOLVES TRADE-OFFS BETWEEN ACCURACY AND SPEED, AND IT IS NECESSARY TO FIND THE OPTIMAL SOLUTION IN LIGHT OF THE ORIGINAL OBJECTIVE. IN SOME CASES, IT IS DESIRABLE FOR VENDORS TO BE ABLE TO PROPOSE THE BEST WAY FORWARD IN LINE WITH BUSINESS REQUIREMENTS, INCLUDING THE DECISION TO ABANDON EDGE AI (FOR EXAMPLE, BY CONSIDERING ALTERNATIVE METHODS SUCH AS GAMING PCS).
EDGE AI SOLUTIONS FROM ARAYAアラヤ
AT ARAYAアラヤ, WE PROVIDE EDGE AI SOLUTIONS AND HAVE EXPERIENCE IN LIGHTWEIGHTING MODELS AND IMPLEMENTING THEM IN SYSTEMS FOR A VARIETY OF USE CASES.
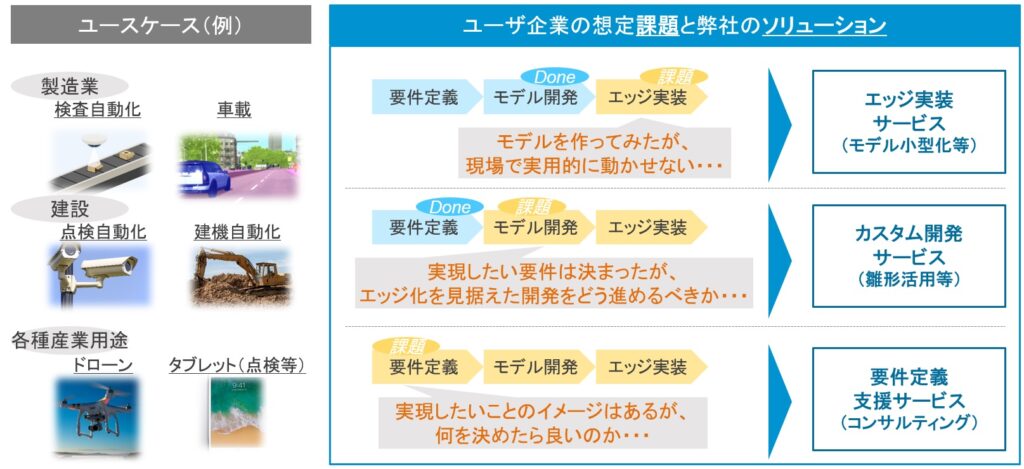
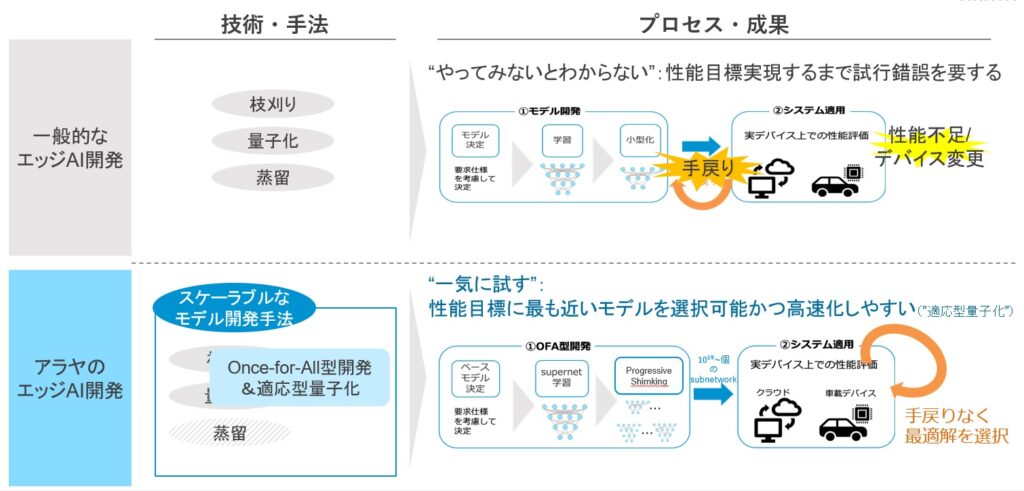
Our expertise in model weight reduction and embedded development in devices enables us to support efficient edge AI implementation (scalable model development), such as realizing requirements with minimum trial and error. Our experience with a wide range of edge devices enables us to develop the most appropriate methodologies for the devices specified by the client. Even if you don't need to define the details of your development, Arayaアラヤwill propose the best development method for your high-level requirements.
IF YOU HAVE A NEED FOR EDGE AI IMPLEMENTATION, PLEASE DO NOT HESITATE TO CONTACT US.
You can find out more about Arayaアラヤ's Edge AI services here.
Articles
(1) The latest trends in edge AI technology
(2) Five points to consider when implementing edge AI (this article)

